Category Archives: Automation
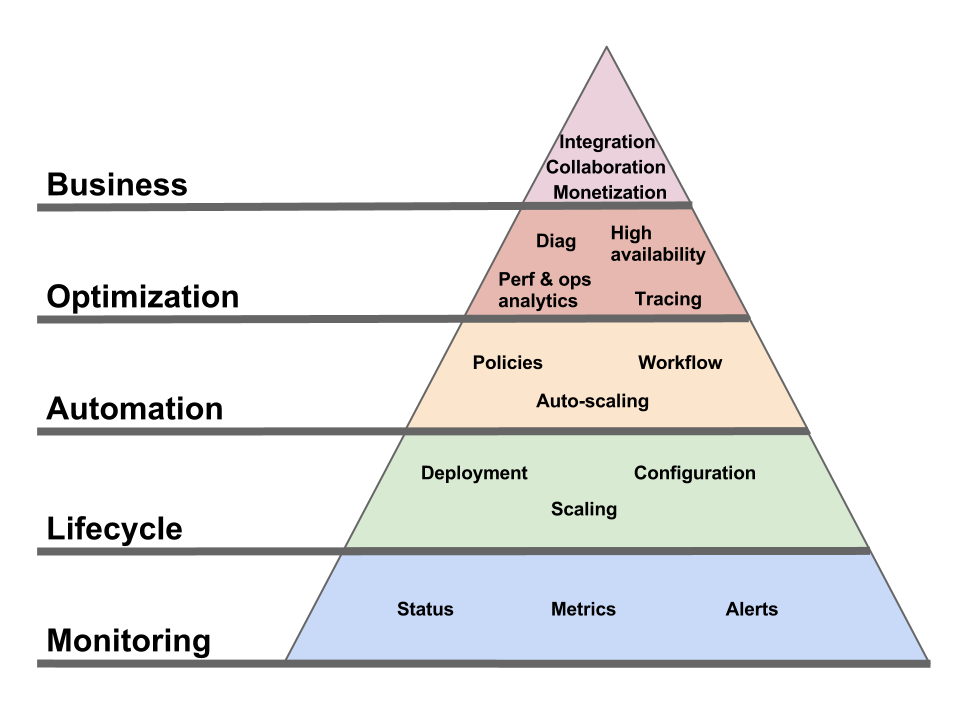
Pyramid of needs for Cloud management
Comments Off on Pyramid of needs for Cloud management
Filed under Application Mgmt, Automation, Business, Cloud Computing, Everything, Governance, IT Systems Mgmt, Manageability, Utility computing
GAE Traffic Splitting
Interesting addition to the Google App Engine (GAE) platform in release 1.6.3: Traffic Splitting lets you run several versions of your application (using a DNS sub-domain for each version) and choose to direct a certain percentage of requests to a specific version. This lets you, among other things, slowly phase in your updates and test the result on a small set of users.
That’s nice, but until I read the documentation for the feature I had assumed (and hoped) it was something else.
Rather than using traffic splitting to test different versions of my app (something which the platform now makes convenient but which I could have implemented on my own), it would be nice if that mechanism could be used to test updates to the GAE platform itself. As described in “Come for the PaaS Functional Model, stay for the Cloud Operational Model“, it’s wishful thinking to assume that changes to the PaaS platform (an update applied by Google admins) cannot have a negative effect on your application. In other words, “When NoOps meets Murphy’s Law, my money is on Murphy“.
What would be nice is if Google could give application owners advanced warning of a platform change and let them use the Traffic Splitting feature to direct a portion of the incoming requests to application instances running on the new platform. And also a way to include the platform version in all log messages.
Here’s the issue as I described it in the aforementioned “Cloud Operational Model” post:
In other words, if a patch or update is worth testing in a staging environment if you were to apply it on-premise, what makes you think that it’s less likely to cause a problem if it’s the Cloud provider who rolls it out? Sure, in most cases it will work just fine and you can sing the praise of “NoOps”. Until the day when things go wrong, your users are affected and you’re taken completely off-guard. Good luck debugging that problem, when you don’t even know that an infrastructure change is being rolled out and when it might not even have been rolled out uniformly across all instances of your application.
How is that handled in your provider’s Operational Model? Do you have visibility into the change schedule? Do you have the option to test your application on the new infrastructure or to at least influence in any way how and when the change gets rolled out to your instances?
Hopefully, the addition of Traffic Splitting to Google App Engine is a step towards addressing that issue.
Filed under Application Mgmt, Automation, Cloud Computing, DevOps, Everything, Google, Google App Engine, Utility computing
Come for the PaaS Functional Model, stay for the Cloud Operational Model
The Functional Model of PaaS is nice, but the Operational Model matters more.
Let’s first define these terms.
The Functional Model is what the platform does for you. For example, in the case of AWS S3, it means storing objects and making them accessible via HTTP.
The Operational Model is how you consume the platform service. How you request it, how you manage it, how much it costs, basically the total sum of the responsibility you have to accept if you use the features in the Functional Model. In the case of S3, the Operational Model is made of an API/UI to manage it, a bill that comes every month, and a support channel which depends on the contract you bought.
The Operational Model is where the S (“service”) in “PaaS” takes over from the P (“platform”). The Operational Model is not always as glamorous as new runtime features. But it’s what makes Cloud Cloud. If a provider doesn’t offer the specific platform feature your application developers desire, you can work around it. Either by using a slightly-less optimal approach or by building the feature yourself on top of lower-level building blocks (as Netflix did with Cassandra on EC2 before DynamoDB was an option). But if your provider doesn’t offer an Operational Model that supports your processes and business requirements, then you’re getting a hipster’s app server, not a real PaaS. It doesn’t matter how easy it was to put together a proof-of-concept on top of that PaaS if using it in production is playing Russian roulette with your business.
If the Cloud Operational Model is so important, what defines it and what makes a good Operational Model? In short, the Operational Model must be able to integrate with the consumer’s key processes: the business processes, the development processes, the IT processes, the customer support processes, the compliance processes, etc.
To make things more concrete, here are some of the key aspects of the Operational Model.
Deployment / configuration / management
I won’t spend much time on this one, as it’s the most understood aspect. Most Clouds offer both a UI and an API to let you provision and control the artifacts (e.g. VMs, application containers, etc) via which you access the PaaS functional interface. But, while necessary, this API is only a piece of a complete operational interface.
Support
What happens when things go wrong? What support channels do you have access to? Every Cloud provider will show you a list of support options, but what’s really behind these options? And do they have the capability (technical and logistical) to handle all your issues? Do they have deep expertise in all the software components that make up their infrastructure (especially in PaaS) from top to bottom? Do they run their own datacenter or do they themselves rely on a customer support channel for any issue at that level?
SLAs
I personally think discussions around SLAs are overblown (it seems like people try to reduce the entire Cloud Operational Model to a provisioning API plus an SLA, which is comically simplistic). But SLAs are indeed part of the Operational Model.
Infrastructure change management
It’s very nice how, in a PaaS setting, the Cloud provider takes care of all change management tasks (including patching) for the infrastructure. But the fact that your Cloud provider and you agree on this doesn’t neutralize Murphy’s law any more than me wearing Michael Jordan sneakers neutralizes the law of gravity when I (try to) dunk.
In other words, if a patch or update is worth testing in a staging environment if you were to apply it on-premise, what makes you think that it’s less likely to cause a problem if it’s the Cloud provider who rolls it out? Sure, in most cases it will work just fine and you can sing the praise of “NoOps”. Until the day when things go wrong, your users are affected and you’re taken completely off-guard. Good luck debugging that problem, when you don’t even know that an infrastructure change is being rolled out and when it might not even have been rolled out uniformly across all instances of your application.
How is that handled in your provider’s Operational Model? Do you have visibility into the change schedule? Do you have the option to test your application on the new infrastructure or to at least influence in any way how and when the change gets rolled out to your instances?
Note: I’ve covered this in more details before and so has Chris Hoff.
Diagnostic
Developers have assembled a panoply of diagnostic tools (memory/thread analysis, BTM, user experience, logging, tracing…) for the on-premise model. Many of these won’t work in PaaS settings because they require a console on the local machine, or an agent, or a specific port open, or a specific feature enabled in the runtime. But the need doesn’t go away. How does your PaaS Operational Model support that process?
Customer support
You’re a customer of your Cloud, but you have customers of your own and you have to support them. Do you have the tools to react to their issues involving your Cloud-deployed application? Can you link their service requests with the related actions and data exposed via your Cloud’s operational interface?
Security / compliance
Security is part of what a Cloud provider has to worry about. The problem is, it’s a very relative concept. The issue is not what security the Cloud provider needs, it’s what security its customers need. They have requirements. They have mandates. They have regulations and audits. In short, they have their own security processes. The key question, from their perspective, is not whether the provider’s security is “good”, but whether it accommodates their own security process. Which is why security is not a “trust us” black box (I don’t think anyone has coined “NoSec” yet, but it can’t be far behind “NoOps”) but an integral part of the Cloud Operational Model.
Business management
The oft-repeated mantra is that Cloud replaces capital expenses (CapExp) with operational expenses (OpEx). There’s a lot more to it than that, but it surely contributes a lot to OpEx and that needs to be managed. How does the Cloud Operational Model support this? Are buyer-side roles clearly identified (who can create an account, who can deploy a service instance, who can manage a deployed instance, etc) and do they map well to the organizational structure of the consumer organization? Can charges be segmented and attributed to various cost centers? Can quotas be set? Can consumption/cost projections be run?
We all (at least those of us who aren’t accountants) love a great story about how some employee used a credit card to get from the Cloud something that the normal corporate process would not allow (or at too high a cost). These are fun for a while, but it’s not sustainable. This doesn’t mean organizations will not be able to take advantage of the flexibility of Cloud, but they will only be able to do it if the Cloud Operational Model provides the needed support to meet the requirements of internal control processes.
Conclusion
Some of the ways in which the Cloud Operational Model materializes can be unexpected. They can seem old-fashioned. Let’s take Amazon Web Services (AWS) as an example. When they started, ownership of AWS resources was tied to an individual user’s Amazon account. That’s a big Operational Model no-no. They’ve moved past that point. As an illustration of how the Operational Model materializes, here are some of the features that are part of Amazon’s:
- You can Fedex a drive and have Amazon load the data to S3.
- You can optimize your costs for flexible workloads via spot instances.
- The monitoring console (and API) will let you know ahead of time (when possible) which instances need to be rebooted and which will need to be terminated because they run on a soon-to-be-decommissioned server. Now you could argue that it’s a limitation of the AWS platform (lack of live migration) but that’s not the point here. Limitations exists and the role of the Operational Model is to provide the tools to handle them in an acceptable way.
- Amazon has a program to put customers in touch with qualified System Integrators.
- You can use your Amazon support channel for questions related to some 3rd party software (though I don’t know what the depth of that support is).
- To support your security and compliance requirements, AWS support multi-factor authentication and has achieved some certifications and accreditations.
- Instance status checks can help streamline your diagnostic flows.
These Operational Model features don’t generate nearly as much discussion as new Functional Model features (“oh, look, a NoSQL AWS service!”) . That’s OK. The Operational Model doesn’t seek the limelight.
Business applications are involved, in some form, in almost every activity taking place in a company. Those activities take many different forms, from a developer debugging an application to an executive examining operational expenses. The PaaS Operational Model must meet their needs.
MacOS Automator workflow to populate iTunes info from file path
Just in case someone has the same need, here is an Automator workflow to update the metadata of a music (or video) file based on the file’s path (for non-Mac users, Automator is a graphical task automation tool in MacOS).
Here the context: I recently bought my first Mac, a home desktop. That’s where my MP3 reside now, carefully arranged in folders by artist name. I made sure to plop them in the default “Music” folder, to make iTunes happy. Or so I thought, until I actually started iTunes and saw it attempt to copy every single MP3 file in its own directory. Pretty stupid, but easily fixed via a config setting. The next issue is that, within iTunes, you cannot organize your music based on the directory structure. All it cares about is the various metadata fields. You can’t even display the file name or the file path in the main iTunes window.
Leave it to Apple to create a Unix operating system which hates files.
The obvious solution is to dump iTunes and look for a better music player. But there’s another problem.
Apparently music equipment manufacturers have given up on organizing your digital music and surrendered that function to Apple (several models let you plug an SD card or a USB key, but they don’t even try to give you a decent UI to select the music from these drives). They seem content to just sell amplifiers and speakers, connected to an iPod doc. Strange business strategy, but what do I know. So I ended up having to buy an iPod Classic for my living room, even though I have no intention of ever taking it off the dock.
And the organization in the iPod is driven by the same metadata used by iTunes, so even if I don’t want to use iTunes on the desktop I still have to somehow transfer the organization reflected in my directory structure into Apple’s metadata fields. At least the artist name; I don’t care for albums, albums mean nothing. And of course I’m not going to do this manually over many gigabytes of data.
The easy way would be to write a Python script since apparently some kind souls have written Python modules to manipulate iTunes metadata.
But I am still in my learn-to-use-MacOS phase, so I force myself to use the most MacOS-native solution, as a learning experience. Which took me to Automator and to the following workflow:

OK, I admit it’s not fully MacOS-native, I had to escape to a shell to run a regex; I couldn’t find a corresponding Automator action.
I run it as a service, which can be launched either on a subfolder of “Music” (e.g. “Leonard Cohen”) or on a set of files which are in one of these subfolders. It just picks the name of the subfolder (“Leonard Cohen” in this case) and sets that as the “artist” in the file’s metadata.
Side note: this assumes you Music folder is “/Users/vbp/Music”, you should replace “vbp” with your account user name.
For the record, there is a utility that helps you debug workflows. It’s “/System/Library/CoreServices/pbs”. I started the workflow by making it apply to “iTunes files” and later changed it to work on “files and folders”. And yet it didn’t show up in the service list for folders. Running “pbs -debug” showed that my workflow logged NSSendFileTypes=(“public.audio”); no matter what. Looks like a bug to me, so I just created a new workflow with the right input type from the start and that fixed it.
Not impressed with iTunes, but I got what I needed.
[UPDATE]
I’ve improved it a bit, in two ways. First I’ve generalized the regex so that it can be applied to files in any location and it will pick up the name of the parent folder. Second, I’m now processing files one by one so that they don’t all have to be in the same folder (the previous version grabs the folder name once and applies it to all files, the new version retrieves the folder name for each file). This way, you can just select your Music folder and run this service on it and it will process all the files.
It’s pretty inefficient and the process can take a while if you have lots of files. You may want to add another action at the end (e.g. play a sound or launch the calculator app) just to let you know that it’s done.
In the new version, you need to first create this workflow and save it (as a workflow) to a file:

Then you create this service which references the previous workflow (here I named it “assign artist based on parent folder name”). This service is what you invoke on the folders and files:

I haven’t yet tried running more than one workflow at a time to speed things up. I assume the variables are handled as local variables, not global, but it was too late at night to open this potential can of worms.
Filed under Apple, Automation, Everything, Off-topic
DMTF publishes draft of Cloud API
Note to anyone who still cares about IaaS standards: the DMTF has published a work in progress.
There was a lot of interest in the topic in 2009 and 2010. Some heated debates took place during Cloud conferences and a few symposiums were organized to try to coordinate various standard efforts. The DMTF started an “incubator” on the topic. Many companies brought submissions to the table, in various levels of maturity: VMware, Fujitsu, HP, Telefonica, Oracle and RedHat. IBM and Microsoft might also have submitted something, I can’t remember for sure.
The DMTF has been chugging along. The incubator turned into a working group. Unfortunately (but unsurprisingly), it limited itself to the usual suspects (and not all the independent Cloud experts out there) and kept the process confidential. But this week it partially lifted the curtain by publishing two work-in-progress documents.
They can be found at http://dmtf.org/standards/cloud but if you read this after March 2012 they won’t be there anymore, as DMTF likes to “expire” its work-in-progress documents. The two docs are:
- Cloud Infrastructure Management Interface (CIMI) Model and REST Interface Specification, and
- Cloud Infrastructure Management Interface – Common Information Model (CIMI-CIM) Specification
The first one is the interesting one, and the one you should read if you want to see where the DMTF is going. It’s a RESTful specification (at the cost of some contortions, e.g. section 4.2.1.3.1). It supports both JSON and XML (bad idea). It plans to use RelaxNG instead of XSD (good idea). And also CIM/MOF (not a joke, see the second document for proof). The specification is pretty ambitious (it covers not just lifecycle operations but also monitoring and events) and well written, especially for a work in progress (props to Gil Pilz).
I am surprised by how little reaction there has been to this publication considering how hotly debated the topic used to be. Why is that?
A cynic would attribute this to people having given up on DMTF providing a Cloud API that has any chance of wide adoption (the adjoining CIM document sure won’t help reassure DMTF skeptics).
To the contrary, an optimist will see this low-key publication as a sign that the passions have cooled, that the trusted providers of enterprise software are sitting at the same table and forging consensus, and that the industry is happy to defer to them.
More likely, I think people have, by now, enough Cloud experience to understand that standardizing IaaS APIs is a minor part of the problem of interoperability (not to mention the even harder goal of portability). The serialization and plumbing aspects don’t matter much, and if they do to you then there are some good libraries that provide mappings for your favorite language. What matters is the diversity of resources and services exposed by Cloud providers. Those choices strongly shape the design of your application, much more than the choice between JSON and XML for the control API. And nobody is, at the moment, in position to standardize these services.
So congrats to the DMTF Cloud Working Group for the milestone, and please get the API finalized. Hopefully it will at least achieve the goal of narrowing down the plumbing choices to three (AWS, OpenStack and DMTF). But that’s not going to solve the hard problem.
“Toyota Friend”: It’s cool! It’s social! It’s cloud! It’s… spam.
Michael Coté has it right: “all roads lead to better junk mail.”
We can take “road” literally in this case since Toyota has teamed up with Salesforce.com to “build Toyota Friend social network for Toyota customers and their cars“.
If you’re tired of “I am getting a fat-free decaf latte at Starbucks” FourSquare messages, wait until you start receiving “my car is getting a lead-free 95-octane pure arabica gas refill at Chevron”. That’s because Toyota owners will get to “choose to extend their communication to family, friends, and others through public social networks such as Twitter and Facebook“.
Leaving “family and friends” aside (they will beg you to), the main goal of this social network is to connect “Toyota customers with their cars, their dealership, and with Toyota”. And what for purpose? The press release has an example:
For example, if an EV or PHV is running low on battery power, Toyota Friend would notify the driver to re-charge in the form of a “tweet”-like alert.
That’s pretty handy, but every car I’ve ever owned has sent me a “tweet-like” alert in the form of a light on the dashboard when I got low on fuel.
Toyota’s partner, Salesforce, also shares its excitement about this (they bring the Cloud angle), and offers another example of its benefits:
Would you like to know if your dealer’s service department has a big empty space on its calendar tomorrow morning, and is willing to offer you a sizable discount on routine service if you’ll bring the car in then instead of waiting another 100 miles?
Ten years ago, the fancy way to justify spamming people was to say that you offered “personalization”. Look at this old advertisement (which lists Toyota as a customer) about how “personalization” is the way to better connect with customers and get them to buy more. Today, we’ve replaced “personalization” with “social media” but it’s the exact same value proposition to the company (coupled with a shiny new way to feed it to its customers).
BTW, the company behind the advertisement? Broadvision. Remember Broadvision? Internet bubble darling, its share price hit over $20,000 (split-adjusted to today). According to the ad above, it was at the time “the world’s second leading e-commerce vendor in terms of licensing revenues, just behind Netscape and ahead of Oracle, IBM, and even Microsoft” and “the Internet commerce firm listed in Bloomberg’s Top 100 Stocks”. Today, it’s considered a Micro-cap stock. Which reminds me, I still haven’t gotten around to buying some LinkedIn…
Notice who’s missing from the list of people you’ll connect to using Toyota’s social network? Independent repair shops and owners forums (outside Toyota). Now, if this social network was used to let me and third-party shops retrieve all diagnostic information about my car and all related knowledge from Toyota and online forums that would be valuable. But that’s the last thing on earth Toyota wants.
A while ago, a strange-looking icon lit up on the dashboard of my Prius. Looking at it, I had no idea what it meant. A Web search (which did not land on Toyota’s site of course) told me it indicated low tire pressure (I had a slow leak). Even then, I had no idea which tire it was. Now at that point it’s probably a good idea to check all four of them anyway, but you’d think that with two LCD screens available in the car they’d have a way to show you precise and accurate messages rather than cryptic icons. It’s pretty clear that the whole thing is designed with the one and only goal of making you go to your friendly Toyota dealership.
Which is why, without having seen this “Toyota Friend” network in action, I am pretty sure I know it will be just another way to spam me and try to scare me away from bringing my car anywhere but to Toyota.
Dear Toyota, I don’t want “social”, I want “open”.
In the meantime, and since you care about my family, please fix the problem that is infuriating my Japanese-American father in law: that the voice recognition in his Japan-made car doesn’t understand his accented English. Thanks.
Comments Off on “Toyota Friend”: It’s cool! It’s social! It’s cloud! It’s… spam.
Filed under Automation, Business, Cloud Computing, Everything, Off-topic
Reading IBM’s proposed standard for Cloud Architecture
Did you enjoy the first version of IBM’s Cloud Computing Reference Architecture? Did you even get certified on it? Then rejoice, because there’s a new version. IBM recently submitted the IBM Cloud Computing Reference Architecture 2.0 to The Open Group.
I’m a bit out of practice reading this kind of IBMese (let’s just say that The Open Group was the right place to submit it) but I would never let my readers down. So, even though these box-within-a-box-within-a-box diagrams (see section 2) give me flashbacks to the days of OGF and WSRF, I soldiered on.
I didn’t understand the goal of the document enough to give you a fair summary, but I can share some thoughts.
It starts by talking a lot about SOA. I initially thought this was to make the point that Glen Daniels articulated very well in this tweet:
Yup, correct SOA patterns (loose coupling, dyn refs, coarse interfaces…) are exactly what you need for cloud apps. You knew this.
But no. Rather than Glen’s astute remark, IBM’s point is one meta-level lower. It’s that “Cloud solutions are SOA solutions”. Which I have a harder time parsing. If you though “service” was overloaded before…
While some of the IBM authors are SOA experts, others apparently come from a Telco background so we get OSS/BSS analogies next.
By that point, I’ve learned that Cloud is like SOA except when it’s like Telco (but there’s probably another reference architecture somewhere that explains that Telco is SOA, so it all adds up).
One thing that chagrined me was that even though this document is very high-level it still manages to go down into implementatin technologies long enough to assert, wrongly, that virtualization is required for Cloud solutions. Another Cloud canard repeated here is the IaaS/PaaS/SaaS segmentation of the Cloud world, to which IBM adds a BPaaS (Business Process as a Service) layer for good measure (for my take on how Cloud relates to SOA, and how I dislike the IaaS/PaaS/SaaS pyramid, see this write-up of the presentation I gave at last year’s Cloud Connect, especially the 3rd picture).
It gets a lot better if you persevere to page 29, where the “Architecture Principles” finally get introduced (if had been asked to edit the paper, I would have only kept the last 6 pages). They are:
- Design for Cloud-scale Efficiencies: When realizing cloud characteristics such as elasticity, self-service access, and flexible sourcing, the cloud design is strictly oriented to high cloud scale efficiencies and short time-to-delivery/time-to-change. (“Efficiency Principle”)
- Support Lean Service Management: The Common Cloud Management Platform fosters lean and lightweight service management policies, processes, and technologies. (“Lightweightness Principle”)
- Identify and Leverage Commonalities: All commonalities are identified and leveraged in cloud service design. (“Economies-of-scale principle”)
- Define and Manage generically along the Lifecycle of Cloud Services: Be generic across I/P/S/BPaaS & provide ‘exploitation’ mechanism to support various cloud services using a shared, common management platform (“Genericity”).
Each principle gets a nickname, thanks to which IBM can refer to this list as the ELEG principles (Efficiency, Lightweightness, Economies-of-scale, Genericity). It also spells GLEE, but apparently that’s wasn’t the prefered sequence.
The first principle is hard to disagree with. The second also rings true, including its dings on ITIL (but the irony of IBM exhaulting “Lightweightness” is hard to ignore). The third and fourth principles (by that time I had lost too many brain cells to understand how they differ) really scared me. While I can understand the motivation, they elicited a vision of zombies in blue suits (presumably undead IBM Distinguish Engineers and Fellows) staggering towards me: “frameworks… we want frameworks…”.
There you go. If you want more information (and, more importantly, unbiased information) go read the Reference Architecture yourself. I am not involved in The Open Group, and I have no idea what it plans to do with it (and if it has received other submissions of the same type). Though I wouldn’t be surprised if I see, in 5 years, some panic sales rep asking an internal mailing list “The customer RPF asks for a mapping of our solution to the Open Group Cloud Reference Architecture and apparently IBM has 94 slides about it, what do I do? Has anyone heard about this Reference Architecture? This is urgent.”
Urgent things are long in the making.
CloudFormation in context
I’ve been very positive about AWS CloudFormation (both in tweet and blog form) since its announcement . I want to clarify that it’s not the technology that excites me. There’s nothing earth-shattering in it. CloudFormation only covers deployment and doesn’t help you with configuration, monitoring, diagnostic and ongoing lifecycle. It’s been done before (including probably a half-dozen times within IBM alone, I would guess). We’ve had much more powerful and flexible frameworks for a long time (I can’t even remember when SmartFrog first came out). And we’ve had frameworks with better tools (though history suggests that tools for CloudFormation are already in the works, not necessarily inside Amazon).
Here are some non-technical reasons why I tweeted that “I have a feeling that the AWS CloudFormation format might become an even more fundamental de-facto standard than the EC2 API” even before trying it out.
It’s simple to use. There are two main reasons for this (and the fact that it uses JSON rather than XML is not one of them):
– It only support a small set of features
– It “hard-codes” resource types (e.g. EC2, Beanstalk, RDS…) rather than focusing on an abstract and extensible mechanism
It combines a format and an API. You’d think it’s obvious that the two are complementary. What can you do with a format if you don’t have an API to exchange documents in that format? Well, turns out there are lots of free-floating model formats out there for which there is no defined API. And they are still wondering why they never saw any adoption.
It merges IaaS and PaaS. AWS has always defied the “IaaS vs. PaaS” view of the Cloud. By bridging both, CloudFormation is a great way to provide a smooth transition. I expect most of the early templates to be very EC2-centric (are as most AWS deployments) and over time to move to a pattern in which EC2 resources are just used for what doesn’t fit in more specialized containers).
It comes at the right time. It picks the low-hanging fruits of the AWS automation ecosystem. The evangelism and proof of concept for templatized deployments have already taken place.
It provides a natural grouping of the various AWS resources you are currently consuming. They are now part of an explicit deployment context.
It’s free (the resources provisioned are not free, of course, but the fact that they came out of a CloudFormation deployment doesn’t change the cost).
Comments Off on CloudFormation in context
Filed under Amazon, Application Mgmt, Automation, Cloud Computing, Everything, Mgmt integration, Modeling, PaaS, Specs, Utility computing
AWS CloudFormation is the iPhone of Cloud services
Expanding on tweet that I wrote soon after the announcement of AWS CloudFormation.
The iPhone unifies the GPS, phone, PDA, camera and camcorder. CloudFormation does the same for infrastructure services (VMs, volumes, network…) and some platform services (Beanstalk, RDS, SimpleDB, SQS, SNS…). You don’t think about whether you should grab a phone or a PDA, you grab an iPhone and start using the feature you need. It’s the default tool. Similarly with CloudFormation, you won’t start by thinking about what AWS service you want to use. Rather, you grab a CloudFormation template and modify it as needed. The template (or the template editor) is the default tool.
The iPhone doesn’t just group features that used to be provided by many devices. It also allows these features to collaborate. It’s not that you get a PDA and a phone side-by-side in one device. You can press the “call” button from the “PDA” feature. CloudFormation doesn’t just bundle deployments to various AWS services, it wires them together.
Anyone can write apps for the iPhone. Anyone can write apps that use CloudFormation.
There’s an App Store for iPhone apps. On the CloudFormation side, it will probably come soon (right now Amazon has made templates available on S3, but that’s not a real store). Amazon has developed example templates for a set of common applications, but expect application authors to take ownership of that task soon. They’ll consider it one of their deliverables. Right next to the “download” button you’ll start seeing a “deploy to AWS” button. Guess which one will eventually be used the most?
It’s Apple’s platform and your applications have to comply with their policy. AWS is not as much of a control freak as Apple and doesn’t have an upfront approval process, but it has its terms of service and they too can get you kicked out.
The iPhone is not a standard platform (though you may consider it a de-facto standard). Same for AWS CloudFormation.
There are alternatives to the iPhone that define themselves primarily as being more open than it, mainly Android. Same for AWS with OpenStack (which probably will soon have its CloudFormation equivalent).
The iPhone infiltrated itself into corporations at the ground level, even if the CIO initially saw no reason to look beyond BlackBerry for corporate needs. Same with AWS.
Any other parallel? Any fundamental difference I missed?
The API, the whole API and nothing but the API
When programming against a remote service, do you like to be provided with a library (or service stub) or do you prefer “the API, the whole API, nothing but the API”?
A dedicated library (assuming it is compatible with your programming language of choice) is the simplest way to get invocations flowing. On the other hand, if you expect your client to last longer than one night of tinkering then you’re usually well-advised to resist making use of such a library in your code. Save yourself license issues, support issues, packaging issues and lifecycle issues. Also, decide for yourself what the right interaction model with the remote API is for your app.
One of the key motivations of SOAP was to prevent having to get stubs from the service provider. That remains an implicit design goals of the recent HTTP APIs (often called “RESTful”). You should be able to call the API directly from your application. If you use a library, e.g. an authentication library, it’s a third party library, not one provided by the service provider you are trying to connect to.
So are provider-provided (!) libraries always bad? Not necessarily, they can be a good learning/testing tool. Just don’t try to actually embed them in your app. Use them to generate queries on the wire that you can learn from. In that context, a nice feature of these libraries is the ability to write out the exact message that they put on the wire so you don’t have to intercept it yourself (especially if messages are encrypted on the wire). Even better if you can see the library code, but even as a black box they are a pretty useful way to clarify the more obscure parts of the API.
A few closing comments:
– In a way, this usage pattern is similar to a tool like the WLST Recorder in the WebLogic Administration Console. You perform the actions using the familiar environment of the Console, and you get back a set of WLST commands as a starting point for writing your script. When you execute your script, there is no functional dependency on the recorder, it’s a WLST script like any other.
– While we’re talking about downloadable libraries that are primarily used as a learning/testing tool, a test endpoint for the API would be nice too (either as part of the library or as a hosted service at a well-known URL). In the case of most social networks, you can create a dummy account for testing; but some other services can’t be tested in a way that is as harmless and inexpensive.
– This question of provider-supplied libraries is one of the reasons why I lament the use of the term “API” as it is currently prevalent. Call me old-fashioned, but to me the “API” is the programmatic interface (e.g. the Java interface) presented by the library. The on-the-wire contract is, in my world, called a service contract or a protocol. As in, the Twitter protocol, or the Amazon EC2 protocol, etc… But then again, I was also the last one to accept to use the stupid term of “Cloud Computing” instead of “Utility Computing”. Twitter conversations don’t offer the luxury of articulating such reticence so I’ve given up and now use “Cloud Computing” and “API” in the prevalent way.
[UPDATE: How timely! Seconds after publishing this entry I noticed a new trackback on a previous entry on this blog (Cloud APIs are like military parades). The trackback is an article from ProgrammableWeb, asking the exact same question I am addressing here: Should Cloud APIs Focus on Client Libraries More Than Endpoints?]
Filed under API, Automation, Everything, Implementation, Protocols, REST, SOAP
Cloud APIs are like military parades
The previous post (“Amazon proves that REST doesn’t matter for Cloud APIs”) attracted some interesting comments on the blog itself, on Hacker News and in a response post by Mike Pearce (where I assume the photo is supposed to represent me being an AWS fanboy). I failed to promptly follow-up on it and address the response, then the holidays came. But Mark Little was kind enough to pick the entry up for discussion on InfoQ yesterday which brought new readers and motivated me to write a follow-up.
Mark did a very good job at summarizing my point and he understood that I wasn’t talking about the value (or lack of value) of REST in general. Just about whether it is useful and important in the very narrow field of Cloud APIs. In that context at least, what seems to matter most is simplicity. And REST is not intrinsically simpler.
It isn’t a controversial statement in most places that RPC is easier than REST for developers performing simple tasks. But on the blogosphere I guess it needs to be argued.
Method calls is how normal developers write normal code. Doing it over the wire is the smallest change needed to invoke a remote API. The complexity with RPC has never been conceptual, it’s been in the plumbing. How do I serialize my method call and send it over? CORBA, RMI and SOAP tried to address that, none of them fully succeeded in keeping it simple and yet generic enough for the Internet. XML-RPC somehow (and unfortunately) got passed over in the process.
So what did AWS do? They pretty much solved that problem by using parameters in the URL as a dead-simple way to pass function parameters. And you get the response as an XML doc. In effect, it’s one-half of XML-RPC. Amazon did not invent this pattern. And the mechanism has some shortcomings. But it’s a pragmatic approach. You get the conceptual simplicity of RPC, without the need to agree on an RPC framework that tries to address way more than what you need. Good deal.
So, when Mike asks “Does the fact that AWS use their own implementation of an API instead of a standard like, oh, I don’t know, REST, frustrate developers who really don’t want to have to learn another method of communicating with AWS?” and goes on to answer “Yes”, I scratch my head. I’ve met many developers struggling to understand REST. I’ve never met a developer intimidated by RPC. As to the claim that REST is a “standard”, I’d like to read the spec. Please don’t point me to a PhD dissertation.
That being said, I am very aware that simplicity can come back to bite you, when it’s not just simple but simplistic and the task at hand demands more. Andrew Wahbe hit the nail on the head in a comment on my original post:
Exposing an API for a unique service offered by a single vendor is not going to get much benefit from being RESTful.
Revisit the issue when you are trying to get a single client to work across a wide range of cloud APIs offered by different vendors; I’m willing to bet that REST would help a lot there. If this never happens — the industry decides that a custom client for each Cloud API is sufficient (e.g. not enough offerings on the market, or whatever), then REST may never be needed.
Andrew has the right perspective. The usage patterns for Cloud APIs may evolve to the point where the benefits of following the rules of REST become compelling. I just don’t think we’re there and frankly I am not holding my breath. There are lots of functional improvements needed in Cloud services before the burning issue becomes one of orchestrating between Cloud providers. And while a shared RESTful API would be the easiest to orchestrate, a shared RPC API will still be very reasonably manageable. The issue will mostly be one of shared semantics more than protocol.
Mike’s second retort was that it was illogical for me to say that software developers are mostly isolated from REST because they use Cloud libraries. Aren’t these libraries written by developers? What about these, he asks. Well, one of them, Boto‘s Mitch Garnaat left a comment:
Good post. The vast majority of AWS (or any cloud provider’s) users never see the API. They interact through language libraries or via web-based client apps. So, the only people who really care are RESTafarians, and library developers (like me).
Perhaps it’s possible to have an API that’s so bad it prevents people from using it but the AWS Query API is no where near that bad. It’s fairly consistent and pretty easy to code to. It’s just not REST.
Yup. If REST is the goal, then this API doesn’t reach it. If usefulness is the goal, then it does just fine.
Mike’s third retort was to take issue with that statement I made:
The Rackspace people are technically right when they point out the benefits of their API compared to Amazon’s. But it’s a rounding error compared to the innovation, pragmatism and frequency of iteration that distinguishes the services provided by Amazon. It’s the content that matters.
Mike thinks that
If Rackspace are ‘technically’ right, then they’re right. There’s no gray area. Morally, they’re also right and mentally, physically and spiritually, they’re right.
Sure. They’re technically, mentally, physically and spiritually right. They may even be legally, ethically, metaphysically and scientifically right. Amazon is only practically right.
This is not a ding on Rackspace. They’ll have to compete with Amazon on service (and price), not on API, as they well know and as they are doing. But they are racing against a fast horse.
More generally, the debate about how much the technical merits of an API matters (beyond the point where it gets the job done) is a recurring one. I am talking as a recovering over-engineer.
In a post almost a year ago, James Watters declared that it matters. Mitch Garnaat weighed on the other side: “given how few people use the raw API we probably spend too much time worrying about details“, “maybe we worry too much about aesthetics“, “I still wonder whether we obsess over the details of the API’s a bit too much“ (in case you can’t tell, I’m a big fan of Mitch).
Speaking of people I admire, Shlomo Swidler (“in general, only library developers use the raw HTTP. Everyone else uses a library“) and Joe Arnold (“library integration (fog / jclouds / libcloud) is more important for new #IaaS providers than an API“) make the right point. Rather than spending hours obsessing about the finer points of your API, spend the time writing love letters to Mitch and Adrian so they support you in their libraries (also, allocate less of your design time to RESTfulness and more to the less glamorous subject of error handling).
OK, I’ll pile on two more expert testimonies. Righscale’s Thorsten von Eicken (“the API itself is more a programming exercise than a fundamental issue, it’s the semantics of the resources behind the API that really matter“) and F5’s Lori MacVittie (“the World Doesn’t Care About APIs“).
Bottom line, I see APIs a bit like military parades. Soldiers know better than to walk in tight formation, wearing bright colors and to the sound of fanfare into the battlefield. So why are parade exercises so prevalent in all armies? My guess is that they are used to impress potential enemies, reassure citizens and reflect on the strength of the country’s leaders. But military parades are also a way to ensure internal discipline. You may not need to use parade moves on the battlefield, but the fact that the unit is disciplined enough to perform them means they are also disciplined enough for the tasks that matter. Let’s focus on that angle for Cloud APIs. If your RPC API is consistent enough that its underlying model could be used as the basis for a REST API, you’re probably fine. You don’t need the drum rolls, stiff steps and the silly hats. And no need to salute either.
Filed under Amazon, API, Automation, Cloud Computing, Everything, IT Systems Mgmt, Mgmt integration, Protocols, REST, Specs, Utility computing
Cloud management is to traditional IT management what spreadsheets are to calculators
It’s all in the title of the post. An elevator pitch short enough for a 1-story ride. A description for business people. People who don’t want to hear about models, virtualization, blueprints and devops. But people who also don’t want to be insulted with vague claims about “business/IT alignment” and “agility”.
The focus is on repeatability. Repeatability saves work and allows new approaches. I’ve found spreadsheets (and “super-spreadsheets”, i.e. more advanced BI tools) to be a good analogy for business people. Compared to analysts furiously operating calculators, spreadsheets save work and prevent errors. But beyond these cost savings, they allow you to do things you wouldn’t even try to do without them. It’s not just the same process, done faster and cheaper. It’s a more mature way of running your business.
Same with the “Cloud” style of IT management.
Lifting the curtain on PaaS Cloud infrastructure (can you handle the truth?)
The promise of PaaS is that application owners don’t need to worry about the infrastructure that powers the application. They just provide application artifacts (e.g. WAR files) and everything else is taken care of. Backups. Scaling. Infrastructure patching. Network configuration. Geographic distribution. Etc. All these headaches are gone. Just pick from a menu of quality of service options (and the corresponding price list). Make your choice and forget about it.
In theory.
In practice no abstraction is leak-proof and the abstractions provided by PaaS environments are even more porous than average. The first goal of PaaS providers should be to shore them up, in order to deliver on the PaaS value proposition of simplification. But at some point you also have to acknowledge that there are some irreducible leaks and take pragmatic steps to help application administrators deal with them. The worst thing you can do is have application owners suffer from a leaky abstraction and refuse to even acknowledge it because it breaks your nice mental model.
Google App Engine (GAE) gives us a nice and simple example. When you first deploy an application on GAE, it is deployed as just one instance. As traffic increases, a second instance comes up to handle the load. Then a third. If traffic decreases, one instance may disappear. Or one of them may just go away for no reason (that you’re aware of).
It would be nice if you could deploy your application on what looks like a single, infinitely scalable, machine and not ever have to worry about horizontal scale-out. But that’s just not possible (at a reasonable cost) so Google doesn’t try particularly hard to hide the fact that many instances can be involved. You can choose to ignore that fact and your application will still work. But you’ll notice that some requests take a lot more time to complete than others (which is typically the case for the first request to hit a new instance). And some requests will find an empty local cache even though your application has had uninterrupted traffic. If you choose to live with the “one infinitely scalable machine” simplification, these are inexplicable and unpredictable events.
Last week, as part of the release of the GAE SDK 1.3.8, Google went one step further in acknowledging that several instances can serve your application, and helping you deal with it. They now give you a console (pictured below) which shows the instances currently serving your application.

I am very glad that they added this console, because it clearly puts on the table the question of how much your PaaS provider should open the kimono. What’s the right amount of visibility, somewhere between “one infinitely scalable computer” and giving you fan speeds and CPU temperature?
I don’t know what the answer is, but unfortunately I am pretty sure this console is not it. It is supposed to be useful “in debugging your application and also understanding its performance characteristics“. Hmm, how so exactly? Not only is this console very simple, it’s almost useless. Let me enumerate the ways.
Misleading
Actually it’s worse than useless, it’s misleading. As we can see on the screen shot, two of the instances saw no traffic during the collection period (which, BTW, we don’t know the length of), while the third one did all the work. At the top, we see an “average latency” value. Averaging latency across instances is meaningless if you don’t weight it properly. In this case, all the requests went to the instance that had an average latency of 1709ms, but apparently the overall average latency of the application is 569.7ms (yes, that’s 1709/3). Swell.
No instance identification
What happens when the console is refreshed? Maybe there will only be two instances. How do I know which one went away? Or say there are still three, how do I know these are the same three? For all I know it could be one old instance and two new ones. The single most important data point (from the application administrator’s perspective) is when a new instance comes up. I have no way, in this UI, to know reliably when that happens: no instance identification, no indication of the age of an instance.
Average memory
So we get the average memory per instance. What are we supposed to do with that information? What’s a good number, what’s a bad number? How much memory is available? Is my app memory-bound, CPU-bound or IO-bound on this instance?
Configuration management
As I have described before, change and configuration management in a PaaS setting is a thorny problem. This console doesn’t tackle it. Nowhere does it say which version of the GAE platform each instance is running. Google announces GAE SDK releases (the bits you download), but these releases are mostly made of new platform features, so they imply a corresponding update to Google’s servers. That can’t happen instantly, there must be some kind of roll-out (whether the instances can be hot-patched or need to be recycled). Which means that the instances of my application are transitioned from one platform version to another (and presumably that at a given point in time all the instances of my application may not be using the same platform version). Maybe that’s the source of my problem. Wouldn’t it be nice if I knew which platform version an instance runs? Wouldn’t it be nice if my log files included that? Wouldn’t it be nice if I could request an app to run on a specific platform version for debugging purpose? Sure, in theory all the upgrades are backward-compatible, so it “shouldn’t matter”. But as explained above, “the worst thing you can do is have application owners suffer from a leaky abstraction and refuse to even acknowledge it“.
OK, so the instance monitoring console Google just rolled out is seriously lacking. As is too often the case with IT monitoring systems, it reports what is convenient to collect, not what is useful. I’m sure they’ll fix it over time. What this console does well (and really the main point of this blog) is illustrate the challenge of how much information about the underlying infrastructure should be surfaced.
Surface too little and you leave application administrators powerless. Surface more data but no control and you’ll leave them frustrated. Surface some controls (e.g. a way to configure the scaling out strategy) and you’ve taken away some of the PaaS simplicity and also added constraints to your infrastructure management strategy, making it potentially less efficient. If you go down that route, you can end up with the other flavor of PaaS, the IaaS-based PaaS in which you have an automated way to create a deployment but what you hand back to the application administrator is a set of VMs to manage.
That IaaS-centric PaaS is a well-understood beast, to which many existing tools and management practices can be applied. The “pure PaaS” approach pioneered by GAE is much more of a terra incognita from a management perspective. I don’t know, for example, whether exposing the platform version of each instance, as described above, is a good idea. How leaky is the “platform upgrades are always backward-compatible” assumption? Google, and others, are experimenting with the right abstraction level, APIs, tools, and processes to expose to application administrators. That’s how we’ll find out.
The necessity of PaaS: Will Microsoft be the Singapore of Cloud Computing?
From ancient Mesopotamia to, more recently, Holland, Switzerland, Japan, Singapore and Korea, the success of many societies has been in part credited to their lack of natural resources. The theory being that it motivated them to rely on human capital, commerce and innovation rather than resource extraction. This approach eventually put them ahead of their better-endowed neighbors.
A similar dynamic may well propel Microsoft ahead in PaaS (Platform as a Service): IaaS with Windows is so painful that it may force Microsoft to focus on PaaS. The motivation is strong to “go up the stack” when the alternative is to cultivate the arid land of Windows-based IaaS.
I should disclose that I work for one of Microsoft’s main competitors, Oracle (though this blog only represents personal opinions), and that I am not an expert Windows system administrator. But I have enough experience to have seen some of the many reasons why Windows feels like a much less IaaS-friendly environment than Linux: e.g. the lack of SSH, the cumbersomeness of RDP, the constraints of the Windows license enforcement system, the Windows update mechanism, the immaturity of scripting, the difficulty of managing Windows from non-Windows machines (despite WS-Management), etc. For a simple illustration, go to EC2 and compare, between a Windows AMI and a Linux AMI, the steps (and time) needed to get from selecting an image to the point where you’re logged in and in control of a VM. And if you think that’s bad, things get even worse when we’re not just talking about a few long-lived Windows server instances in the Cloud but a highly dynamic environment in which all steps have to be automated and repeatable.
I am not saying that there aren’t ways around all this, just like it’s not impossible to grow grapes in Holland. It’s just usually not worth the effort. This recent post by RighScale illustrates both how hard it is but also that it is possible if you’re determined. The question is what benefits you get from Windows guests in IaaS and whether they justify the extra work. And also the additional license fee (while many of the issues are technical, others stem more from Microsoft’s refusal to acknowledge that the OS is a commodity). [Side note: this discussion is about Windows as a guest OS and not about the comparative virtues of Hyper-V, Xen-based hypervisors and VMWare.]
Under the DSI banner, Microsoft has been working for a while on improving the management/automation infrastructure for Windows, with tools like PowerShell (which I like a lot). These efforts pre-date the Cloud wave but definitely help Windows try to hold it own on the IaaS battleground. Still, it’s an uphill battle compared with Linux. So it makes perfect sense for Microsoft to move the battle to PaaS.
Just like commerce and innovation will, in the long term, bring more prosperity than focusing on mining and agriculture, PaaS will, in the long term, yield more benefits than IaaS. Even though it’s harder at first. That’s the good news for Microsoft.
On the other hand, lack of natural resources is not a guarantee of success either (as many poor desertic countries can testify) and Microsoft will have to fight to be successful in PaaS. But the work on Azure and many research efforts, like the “next-generation programming model for the cloud” (codename “Orleans”) that Mary Jo Foley revealed today, indicate that they are taking it very seriously. Their approach is not restricted by a VM-centric vision, which is often tempting for hypervisor and OS vendors. Microsoft’s move to PaaS is also facilitated by the fact that, while system administration and automation may not be a strength, development tools and application platforms are.
The forward-compatible Cloud will soon overshadow the backward-compatible Cloud and I expect Microsoft to play a role in it. They have to.
Updates on Microsoft Oslo and “SSH on Windows”
I’ve been tracking the modeling technology previously known as “Microsoft Oslo” with a sympathetic eye for the almost three years since it’s been introduced. I look at it from the perspective of model-driven IT management but the news hadn’t been good on that front lately (except for Douglas Purdy’s encouraging hint).
The prospects got even bleaker today, at least according to the usually-well-informed Mary Jo Foley, who writes: “Multiple contacts of mine are telling me that Microsoft has decided to shelve Quadrant and ‘refocus’ M.” Is “M” the end of the SDM/SML/M model-driven management approach at Microsoft? Or is the “refocus” a hint that M is returning “home” to address IT management use cases? Time (or Doug) will tell…
While we’re talking about Microsoft and IT automation, I have one piece of free advice for the Microsofties: people *really* want to SSH into Windows servers. Here’s how I know. This blog rarely talks about Microsoft but over the course of two successive weekends over a year ago I toyed with ways to remotely manage Windows machines using publicly documented protocols. In effect, showing what to send on the wire (from Linux or any platform) to leverage the SOAP-based management capabilities in recent versions of Windows. To my surprise, these posts (1, 2, 3) still draw a disproportionate amount of traffic. And whenever I look at my httpd logs, I can count on seeing search engine queries related to “windows native ssh” or similar keywords.
If heterogeneous Cloud is something Microsoft cares about they need to better leverage the potential of the PowerShell Remoting Protocol. They can release open-source Python, Java and Ruby client-side libraries. Alternatively, they can drastically simplify the protocol, rather than its current “binary over SOAP” (you read this right) incarnation. Because the poor Kridek who is looking for the “WSDL for WinRM / Remote Powershell” is in for a nasty surprise if he finds it and thinks he’ll get a ready-to-use stub out of it.
That being said, a brave developer willing to suck it up and create such a Python/Ruby/Java library would probably make some people very grateful.
Filed under Application Mgmt, Automation, Everything, Implementation, IT Systems Mgmt, Manageability, Mgmt integration, Microsoft, Modeling, Oslo, Protocols, SML, SOAP, Specs, Tech, WS-Management
CMDB in the Cloud: not your father’s CMDB
Bernd Harzog recently wrote a blog entry to examine whether “the CMDB [is] irrelevant in a Virtual and Cloud based world“. If I can paraphrase, his conclusion is that there will be something that looks like a CMDB but the current CMDB products are ill-equipped to fulfill that function. Here are the main reasons he gives for this prognostic:
- A whole new class of data gets created by the virtualization platform – specifically how the virtualization platform itself is configured in support of the guests and the applications that run on the guest.
- A whole new set of relationships between the elements in this data get created – specifically new relationships between hosts, hypervisors, guests, virtual networks and virtual storage get created that existing CMDB’s were not built to handle.
- New information gets created at a very rapid rate. Hundreds of new guests can get provisioned in time periods much too short to allow for the traditional Extract, Transform and Load processes that feed CMDB’s to be able to keep up.
- The environment can change at a rate that existing CMDB’s cannot keep up with. Something as simple as vMotion events can create thousands of configuration changes in a few minutes, something that the entire CMDB architecture is simply not designed to keep up with.
- Having portions of IT assets running in a public cloud introduces significant data collection challenges. Leading edge APM vendors like New Relic and AppDynamics have produced APM products that allow these products to collect the data that they need in a cloud friendly way. However, we are still a long way away from having a generic ability to collect the configuration data underlying a cloud based IT infrastructure – notwithstanding the fact that many current cloud vendors would not make this data available to their customers in the first place.
- The scope of the CMDB needs to expand beyond just asset and configuration data and incorporate Infrastructure Performance, Applications Performance and Service assurance information in order to be relevant in the virtualization and cloud based worlds.
I wanted to expand on some of these points.
New model elements for Cloud (bullets #1 and #2)
These first bullets are not the killers. Sure, the current CMDBs were designed before the rise of virtualized environment, but they are usually built on a solid modeling foundation that can easily be extend with new resources classes. I don’t think that extending the model to describe VM, VNets, Volumes, hypervisors and their relationships to the physical infrastructure is the real challenge.
New approach to “discovery” (bullets #3 and #4)
This, on the other hand is much more of a “dinosaurs meet meteorite” kind of historical event. A large part of the value provided by current CMDBs is their ability to automate resource discovery. This is often achieved via polling/scanning (at the hardware level) and heuristics/templates (directory names, port numbers, packet inspection, bird entrails…) for application discovery. It’s imprecise but often good enough in static environments (and when it fails, the CMDB complements the automatic discovery with a reconciliation process to let the admin clean things up). And it used to be all you could get anyway so there wasn’t much point complaining about the limitations. The crown jewel of many of today’s big CMDBs can often be traced back to smart start-ups specialized in application discovery/mapping, like Appilog (now HP, by way of Mercury) and nLayers (now EMC). And more recently the purchase of Tideway by BMC (ironically – but unsurprisingly – often cast in Cloud terms).
But this is not going to cut it in “the Cloud” (by which I really mean in a highly automated IT environment). As Bernd Harzog explains, the rate of change can completely overwhelm such discovery heuristics (plus, some of the network scans they sometimes use will get you in trouble in public clouds). And more importantly, there now is a better way. Why discover when you can ask? If resources are created via API calls, there are also API calls to find out which resources exist and how they are configured. This goes beyond the resources accessible via IaaS APIs, like what VMWare, EC2 and OVM let you retrieve. This “don’t guess, ask” approach to discovery needs to also apply at the application level. Rather than guessing what software is installed via packet inspection or filesystem spelunking, we need application-aware discovery that retrieves the application and configuration and dependencies from the application itself (or its underlying framework). And builds a model in which the connections between application entities are expressed in terms of the configuration settings that drive them rather than the side effects by which they can be noticed.
If I can borrow the words of Lew Cirne:
“All solutions built in the pre-cloud era are modeled on jvms (or their equivalent), hosts and ports, rather than the logical application running in a more fluid environment. If the solution identifies a web application by host/port or some other infrastructural id, then you cannot effectively manage it in a cloud environment, since the app will move and grow, and your management system (that is, everything offered by the Big 4, as well as all infrastructure management companies that pay lip service to the application) will provide nearly-useless visibility and extraordinarily high TCO.”
I don’t agree with everything in Lew Cirne’s post, but this diagnostic is correct and well worded. He later adds:
“So application management becomes the strategic center or gravity for the client of a public or private cloud, and infrastructure-centric tools (even ones that claim to be cloudy) take on a lesser role.”
Which is also very true even if counter-intuitive for those who think that
cloud = virtualization (in the “fake machine” interpretation of virtualization)
Embracing such a VM-centric view naturally raises the profile of infrastructure management compared to application management, which is a fallacy in Cloud computing.
Drawing the line between Cloud infrastructure management and application management (bullet #5)
This is another key change that traditional CMDBs are going to have a hard time with. In a Big-4 CMDB, you’re after the mythical “single source of truth”. Even in a federated CMDB (which doesn’t really exist anyway), you’re trying to have a unified logical (if not physical) repository of information. There is an assumption that you want to manage everything from one place, so you can see all the inter-dependencies, across all layers of the stack (even if individual users may have a scope that is limited by permissions). Not so with public Clouds and even, I would argue, any private Cloud that is more than just a “cloud” sticker slapped on an old infrastructure. The fact that there is a clean line between the infrastructure model and the application model is not a limitation. It is empowering. Even if your Cloud provider was willing to expose a detailed view of the underlying infrastructure you should resist the temptation to accept. Despite the fact that it might be handy in the short term and provide an interesting perspective, it is self-defeating in the long term from the perspective of realizing the productivity improvements promised by the Cloud. These improvements require that the infrastructure administrator be freed from application-specific issues and focus on meeting the contract of the platform. And that the application administrator be freed from infrastructure-level concerns (while at the same time being empowered to diagnose application-level concerns). This doesn’t mean that the application and infrastructure models should be disconnected. There is a contract and both models (infrastructure and consumption) should represent it in the same way. It draws a line, albeit one with some width.
Blurring the line between configuration and monitoring (bullet #6)
This is another shortcoming of current CMDBs, but one that I think is more easily addressed. The “contract” between the Cloud infrastructure and the consuming application materializes itself in a mix of configuration settings, administrative capabilities and monitoring data. This contract is not just represented by the configuration-centric Cloud API that immediately comes to mind. It also includes the management capabilities and monitoring points of the resulting instances/runtimes.
Wither CMDB?
Whether all these considerations mean that traditional CMDBs are doomed in the Cloud as Bernd Harzog posits, I don’t know. In this post, BMC’s Kia Behnia acknowledges the importance of application management, though it’s not clear that he agrees with their primacy. I am also waiting to see whether the application management portfolio he has assembled can really maps to the new methods of application discovery and management.
But these are resourceful organization, with plenty of smart people (as I can testify: in the end of my HP tenure I worked with the very sharp CMDB team that came from the Mercury acquisition). And let’s keep in mind that customers also value the continuity of support of their environment. Most of them will be dealing with a mix of old-style and Cloud applications and they’ll be looking for a unified management approach. This helps CMDB incumbents. If you doubt the power to continuity, take a minute to realize that the entire value proposition of hypervisor-style virtualization is centered around it. It’s the value of backward-compatibility versus forward-compatibility. in addition, CMDBs are evolving into CMS and are a lot more than configuration repositories. They are an important supporting tool for IT management processes. Whether, and how, these processes apply to “the Cloud” is a topic for another post. In the meantime, read what the IT Skeptic and Rodrigo Flores have to say.
I wouldn’t be so quick to count the Big-4 out, even though I work every day towards that goal, building Oracle’s application and middleware management capabilities in conjunction with my colleagues focused on infrastructure management.
If the topic of application-centric management in the age of Cloud is of interest to you (and it must be if you’ve read this long entry all the way to the end), You might also find this previous entry relevant: “Generalizing the Cloud vs. SOA Governance debate“.
Dear Cloud API, your fault line is showing
Most APIs are like hospital gowns. They seem to provide good coverage, until you turn around.
I am talking about the dreadful state of fault reporting in remote APIs, from Twitter to Cloud interfaces. They are badly described in the interface documentation and the implementations often don’t even conform to what little is documented.
If, when reading a specification, you get the impression that the “normal” part of the specification is the result of hours of whiteboard debate but that the section that describes the faults is a stream-of-consciousness late-night dump that no-one reviewed, well… you’re most likely right. And this is not only the case for standard-by-committee kind of specifications. Even when the specification is written to match the behavior of an existing implementation, error handling is often incorrectly and incompletely described. In part because developers may not even know what their application returns in all error conditions.
After learning the lessons of SOAP-RPC, programmers are now more willing to acknowledge and understand the on-the-wire messages received and produced. But when it comes to faults, there is still a tendency to throw their hands in the air, write to the application log and then let the stack do whatever it does when an unhandled exception occurs, on-the-wire compliance be damned. If that means sending an HTML error message in response to a request for a JSON payload, so be it. After all, it’s just a fault.
But even if fault messages may only represent 0.001% of the messages your application sends, they still represent 85% of those that the client-side developers will look at.
Client developers can’t even reverse-engineer the fault behavior by hitting a reference implementation (whether official or de-facto) the way they do with regular messages. That’s because while you can generate response messages for any successful request, you don’t know what error conditions to simulate. You can’t tell your Cloud provider “please bring down your user account database for five minutes so I can see what faults you really send me when that happens”. Also, when testing against a live application you may get a different fault behavior depending on the time of day. A late-night coder (or a daytime coder in another time zone) might never see the various faults emitted when the application (like Twitter) is over capacity. And yet these will be quite common at peak time (when the coder is busy with his day job… or sleeping).
All these reasons make it even more important to carefully (and accurately) document fault behavior.
The move to REST makes matters even worse, in part because it removes SOAP faults. There’s nothing magical about SOAP faults, but at least they force you to think about providing an information payload inside your fault message. Many REST APIs replace that with HTTP error codes, often accompanied by a one-line description with a sometimes unclear relationship with the semantics of the application. Either it’s a standard error code, which by definition is very generic or it’s an application-defined code at which point it most likely overlaps with one or more standard codes and you don’t know when you should expect one or the other. Either way, there is too much faith put in the HTTP code versus the payload of the error. Let’s be realistic. There are very few things most applications can do automatically in response to a fault. Mainly:
- Ask the user to re-enter credentials (if it’s an authentication/permission issue)
- Retry (immediately or after some time)
- Report a problem and fail
So make sure that your HTTP errors support this simple decision tree. Beyond that point, listing a panoply of application-specific error codes looks like an attempt to look “RESTful” by overdoing it. In most cases, application-specific error codes are too detailed for most automated processing and not detailed enough to help the developer understand and correct the issue. I am not against using them but what matters most is the payload data that comes along.
On that aspect, implementations generally fail in one of two extremes. Some of them tell you nothing. For example the payload is a string that just repeats what the documentation says about the error code. Others dump the kitchen sink on you and you get a full stack trace of where the error occurred in the server implementation. The former is justified as a security precaution. The latter as a way to help you debug. More likely, they both just reflect laziness.
In the ideal world, you’d get a detailed error payload telling you exactly which of the input parameters the application choked on and why. Not just vague words like “invalid”. Is parameter “foo” invalid for syntactical reasons? Is it invalid because inconsistent with another parameter value in the request? Is it invalid because it doesn’t match the state on the server side? Realistically, implementations often can’t spend too many CPU cycles analyzing errors and generating such detailed reports. That’s fine, but then they can include a link to a wiki a knowledge base where more details are available about the error, its common causes and the workarounds.
Your API should document all messages accurately and comprehensively. Faults are messages too.
Filed under API, Application Mgmt, Automation, Cloud Computing, Everything, Mgmt integration, Protocols, REST, SOAP, Specs, Standards, Tech, Testing, Twitter, Utility computing
The battle of the Cloud Frameworks: Application Servers redux?
The battle of the Cloud Frameworks has started, and it will look a lot like the battle of the Application Servers which played out over the last decade and a half. Cloud Frameworks (which manage IT automation and runtime outsourcing) are to the Programmable Datacenter what Application Servers are to the individual IT server. In the longer term, these battlefronts may merge, but for now we’ve been transported back in time, to the early days of Web programming. The underlying dynamic is the same. It starts with a disruptive IT event (part new technology, part new mindset). 15 years ago the disruptive event was the Web. Today it’s Cloud Computing.
Stage 1
It always starts with very simple use cases. For the Web, in the mid-nineties, the basic use case was “how do I return HTML that is generated by a script as opposed to a static file”. For Cloud Computing today, it is “how do I programmatically create, launch and stop servers as opposed to having to physically install them”.
In that sense, the IaaS APIs of today are the equivalent of the Common Gateway Interface (CGI) circa 1993/1994. Like the EC2 API and its brethren, CGI was not optimized, not polished, but it met the basic use cases and allowed many developers to write their first Web apps (which we just called “CGI scripts” at the time).
Stage 2
But the limitations became soon apparent. In the CGI case, it had to do with performance (the cost of the “one process per request” approach). Plus, the business potential was becoming clearer and attracted a different breed of contenders than just academic and research institutions. So we got NSAPI, ISAPI, FastCGI, Apache Modules, JServ, ZDAC…
We haven’t reached that stage for Cloud yet. That will be when the IaaS APIs start to support events, enumerations, queries, federated identity etc…
Stage 3
Stage 2 looked like the real deal, when we were in it, but little did we know that we were still just nibbling on the hors d’oeuvres. And it was short-lived. People quickly decided that they wanted more than a way to handle HTTP requests. If the Web was going to be central to most programs, then all aspects of programming had to fit well in the context of the Web. We didn’t want Web servers anymore, we wanted application servers (re-purposing a term that had been used for client-server). It needed more features, covering data access, encapsulation, UI frameworks, integration, sessions. It also needed to meet non-functional requirements: availability, scalability (hello clustering), management, identity…
That turned into the battle between the various Java application servers as well as between Java and Microsoft (with .Net coming along), along with other technology stacks. That’s where things got really interesting too, because we explored different ways to attack the problem. People could still program at the HTTP request level. They could use MVC framework, ColdFusion/ASP/JSP/PHP-style markup-driven applications, or portals and other higher-level modular authoring frameworks. They got access to adapters, message buses, process flows and other asynchronous mechanisms. It became clear that there was not just one way to write Web applications. And the discovery is still going on, as illustrated by the later emergence of Ruby on Rails and similar frameworks.
Stage 4
Stage 3 is not over for Web applications, but stage 4 is already there, as illustrated by the fact that some of the gurus of stage 3 have jumped to stage 4. It’s when the Web is everywhere. Clients are everywhere and so are servers for that matter. The distinction blurs. We’re just starting to figure out the applications that will define this stage, and the frameworks that will best support them. The game is far from over.
So what does it mean for Cloud Frameworks?
If, like me, you think that the development of Cloud Frameworks will follow a path similar to that of Application Servers, then the quick retrospective above can be used as a (imperfect) crystal ball. I don’t pretend to be a Middleware historian or that these four stages are the most accurate representation, but I think they are a reasonable perspective. And they hold some lessons for Cloud Frameworks.
It’s early
We are at stage 1. I’ll admit that my decision to separate stages 1 and 2 is debatable and mainly serves to illustrate how early in the process we are with Cloud frameworks. Current IaaS APIs (and the toolkits that support them) are the equivalent of CGI (and the early httpd), something that’s still around (Google App Engine emulates CGI in its Python incarnation) but almost no-one programs to directly anymore. It’s raw, it’s clunky, it’s primitive. But it was a needed starting point that launched the whole field of Web development. Just like IaaS APIs like EC2 have launched the field Cloud Computing.
Cloud Frameworks will need to go through the equivalent of all the other stages. First, the IaaS APIs will get more optimized and capable (stage 2). Then, at stage 3, we will focus on higher-level, more productive abstraction layers (generally referred to as PaaS) at which point we should expect a thousand different approaches to bloom, and several of them to survive. I will not hazard a guess as to what stage 4 will look like (here is my guess for stage 3, in two parts).
No need to rush standards
One benefit of this retrospective is to highlight the tragedy of Cloud standards compared to Web development standards. Wouldn’t we be better off today if the development leads of AWS and a couple of other Cloud providers had been openly cooperating in a Cloud equivalent of the www-talk mailing list of yore? Out of it came a rough agreement on HTML and CGI that allowed developers to write basic Web applications in a reasonably portable way. If the same informal collaboration had taken place for IaaS APIs, we’d have a simple de-facto consensus that would support the low-hanging fruits of basic IaaS. It would allow Cloud developers to support the simplest use cases, and relieve the self-defeating pressure to standardize too early. Standards played a huge role in the development of Application Servers (especially of the Java kind), but that really took place as part of stage 3. In the absence of an equivalent to CGI in the Cloud world, we are at risk of rushing the standardization without the benefit of the experimentation and lessons that come in stage 3.
I am not trying to sugar-coat the history of Web standards. The HTML saga is nothing to be inspired by. But there was an original effort to build consensus that wasn’t even attempted with Cloud APIs. I like the staged process of a rough consensus that covers the basic use cases, followed by experimentation and proprietary specifications and later a more formal standardization effort. If we skip the rough consensus stage, as we did with Cloud, we end up rushing to do final step (to the tune of “customers demand Cloud standards”) even though all we need for now is an interoperable way to meet the basic use cases.
Winners and losers
Whoever you think of as the current leaders of the Application Server battle (hint: I work for one), they were not the obvious leaders of stages 1 and 2. So don’t be in too much of a hurry to crown the Cloud Framework kings. Those you think of today may turn out to be the Netscapes of that battle.
New roles
It’s not just new technology. The development of Cloud Frameworks will shape the roles of the people involved. We used to have designers who thought their job was done when they produced a picture or at best a FrameMaker or QuarkXPress document, which is what they were used to. We had “webmasters” who thought they were set for life with their new Apache skills, then quickly had to evolve or make way, a lesson for IaaS gurus of today. Under terms like “DevOps” new roles are created and existing roles are transformed. Nobody yet knows what will stick. But if I was an EC2 guru today I’d make sure to not get stuck providing just that. Don’t wait for other domains of Cloud expertise to be in higher demand than your current IaaS area, as by then you’ll be too late.
It’s the stack
There aren’t many companies out there making a living selling a stand-alone Web server. Even Zeus, who has a nice one, seems to be downplaying it on its site compared to its application delivery products. The combined pressure of commoditization (hello Apache) and of the demand for a full stack has made it pretty hard to sell just a Web server.
Similarly, it’s going to be hard to stay in business selling just portions of a Cloud Framework. For example, just provisioning, just monitoring, just IaaS-level features, etc. That’s well-understood and it’s fueling a lot of the acquisitions (e.g. VMWare’s purchase of SpringSource which in turn recently purchased RabbitMQ) and partnerships (e.g. recently between Eucalyptus and GroundWork though rarely do such “partnerships” rise to the level of integration of a real framework).
It’s not even clear what the right scope for a Cloud Framework is. What makes a full stack and what is beyond it? Is it just software to manage a private Cloud environment and/or deployments into public Clouds? Does the framework also include the actual public Cloud service? Does it include hardware in some sort of “private Cloud in a box”, of the kind that this recent Dell/Ubuntu announcement seems to be inching towards?
Integration
If indeed we can go by the history of Application Server to predict the future of Cloud Frameworks, then we’ll have a few stacks (with different levels of completeness, standardized or proprietary). This is what happened for Web development (the JEE stack, the .Net stack, a more loosely-defined alternative stack which is mostly open-source, niche stacks like the backend offered by Adobe for Flash apps, etc) and at some point the effort moved from focusing on standardizing the different application environment technology alternatives (e.g. J2EE) towards standardizing how the different platforms can interoperate (e.g. WS-*). I expect the same thing for Cloud Frameworks, especially as they grow out of stages 1 and 2 and embrace what we call today PaaS. At which point the two battlefields (Application Servers and Cloud Frameworks) will merge. And when this happens, I just can’t picture how one stack/framework will suffice for all. So we’ll have to define meaningful integration between them and make them work.
If you’re a spectator, grab plenty of popcorn. If you’re a soldier in this battle, get ready for a long campaign.
Enterprise application integration patterns for IT management: a blast from the past or from the future?
In a recent blog post, Don Ferguson (CTO at CA) describes CA Catalyst, a major architectural overhaul which “applies enterprise application integration patterns to the problem of integrating IT management systems”. Reading this was fascinating to me. Not because the content was some kind of revelation, but exactly for the opposite reason. Because it is so familiar.
For the better part of the last decade, I tried to build just this at HP. In the process, I worked with (and sometimes against) Don’s colleague at IBM, who were on the same mission. Both companies wanted a flexible and reliable integration platform for all aspects of IT management. We had decided to use Web services and SOA to achieve it. The Web services management protocols that I worked on (WSMF, WSDM, WS-Management and the “reconciliation stack”) were meant for this. We were after management integration more than manageability. Then came CMDBf, another piece of the puzzle. From what I could tell, the focus on SOA and Web services had made Don (who was then Mr. WebSphere) the spiritual father of this effort at IBM, even though he wasn’t at the time focused on IT management.
As far as I know, neither IBM nor HP got there. I covered some of the reasons in this post-mortem. The standards bickering. The focus on protocols rather than models. The confusion between the CMDB as a tool for process/service management versus a tool for software integration. Within HP, the turmoil from the many software acquisitions didn’t help, and there were other reasons. I am not sure at this point whether either company is still aiming for this vision or if they are taking a different approach.
But apparently CA is still on this path, and got somewhere. At least according to Don’s post. I have no insight into what was built beyond what’s in the post. I am not endorsing CA Catalyst, just agreeing with the design goals listed by Don. If indeed they have built it, and the integration framework resists the test of time, that’s impressive. And exciting. It apparently even uses some the same pieces we were planning to use, namely WS-Management and CMDBf (I am reluctantly associated with the first and proudly with the second).
While most readers might not share my historical connection with this work, this is still relevant and important to anyone who cares about IT management in the enterprise. If you’re planning to be at CA World, go listen to Don. Web services may have a bad name, but the technical problems of IT management integration remain. There are only a few routes to IT management automation (I count seven, the one taken by CA is #2). You can throw away SOAP if you want, you still need to deal with protocol compatibility, model alignment and instance reconciliation. You need to centralize or orchestrate the management operations performed. You need to be able to integrate with complementary products or at the very least to effectively incorporate your acquisitions. It’s hard stuff.
Bonus point to Don for not forcing a “Cloud” angle for extra sparkle. This is core IT management.
Comments Off on Enterprise application integration patterns for IT management: a blast from the past or from the future?
Filed under Automation, CA, CMDB, CMDB Federation, CMDBf, Everything, IT Systems Mgmt, Mgmt integration, Modeling, People, Protocols, SOAP, Specs, Standards, Tech, Web services, WS-Management
Smoothing a discrete world
For the short term (until we sell one) there are three cars in my household. A manual transmission, an automatic and a CVT (continuous variable transmission). This makes me uniquely qualified to write about Cloud Computing.
That’s because Cloud Computing is yet another area in which the manual/automatic transmission analogy can be put to good use. We can even stretch it to a 4-layer analogy (now that’s elasticity):
Manual transmission
That’s traditional IT. Scaling up or down is done manually, by a skilled operator. It’s usually not rocket science but it takes practice to do it well. At least if you want it to be reliable, smooth and mostly unnoticed by the passengers.
Manumatic transmission (a.k.a. Tiptronic)
The driver still decides when to shift up or down, but only gives the command. The actual process of shifting is automated. This is how many Cloud-hosted applications work. The scale-up/down action is automated but, still contingent on being triggered by an administrator. Which is what most IaaS-deployed apps should probably aspire to at this point in time despite the glossy brochures about everything being entirely automated.
Automatic transmission
That’s when the scale up/down process is not just automated in its execution but also triggered automatically, based on some metrics (e.g. load, response time) and some policies. The scenario described in the aforementioned glossy brochures.
Continuous variable transmission
That’s when the notion of discrete gears goes away. You don’t think in terms of what gear you’re in but how much torque you want. On the IT side, you’re in PaaS territory. You don’t measure the number of servers, but rather a continuously variable application capacity metric. At least in theory (most PaaS implementations often betray the underlying work, e.g. via a spike in application response time when the app is not-so-transparently deployed to a new node).
More?
OK, that’s the analogy. There are many more of the same kind. Would you like to hear how hybrid Cloud deployments (private+public) are like hybrid cars (gas+electric)? How virtualization is like carpooling (including how you can also be inconvenienced by the BO of a co-hosted VM)? Do you want to know why painting flames on the side of your servers doesn’t make them go faster?
Driving and IT management have a lot in common, including bringing out the foul-mouth in us when things go wrong.
So, anyone wants to buy a manual VW Golf Turbo? Low mileage. Cloud-checked.