Category Archives: Business
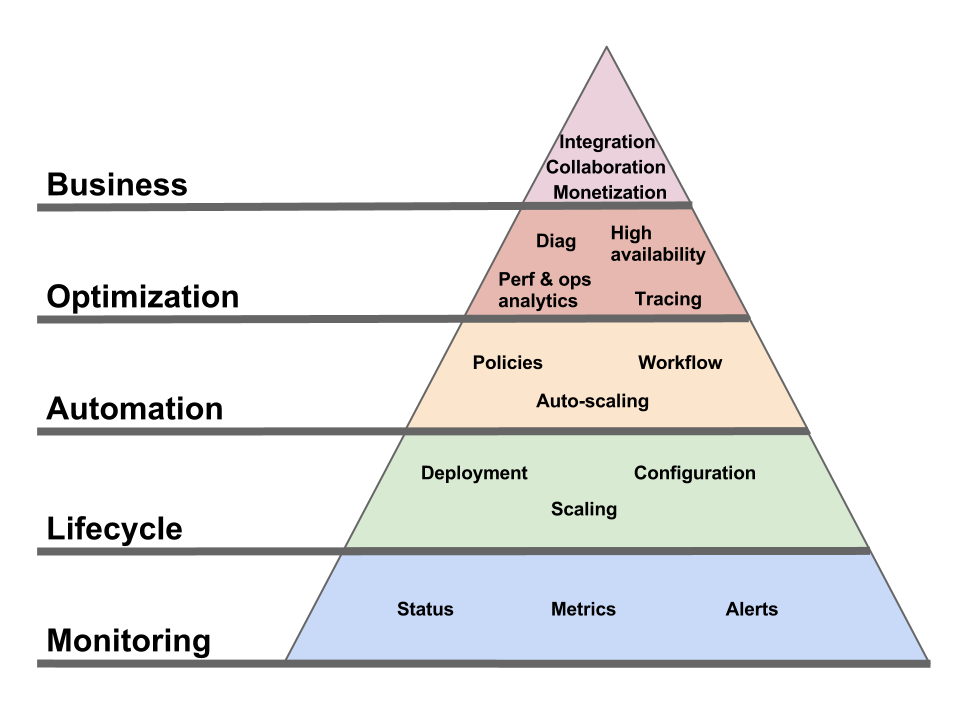
Pyramid of needs for Cloud management
Comments Off on Pyramid of needs for Cloud management
Filed under Application Mgmt, Automation, Business, Cloud Computing, Everything, Governance, IT Systems Mgmt, Manageability, Utility computing
Are you the dumb money in the Cloud?
Another paper came out measuring the performance diversity of Cloud VMs within the same advertised type. Here’s the paper (PDF), here are the slides (PDF) and here is the video (this was presented back in June but I hadn’t seen it until today’s post in the High Scalability blog). Once again, the research shows a large discrepancy. The authors assert that “by selecting better-performing instances to complete the same task, end-users of Amazon EC2 platform can achieve up to 30% cost saving”.
I’ve heard people describing how they use “instance tasting”. Every time they get a new instance, they run performance tests (either on CPU like this paper, or i/o, or both, depending on how they plan to use the VM). They quickly terminate the instances that don’t perform well, to improve their bang/buck ratio. I don’t know how prevalent that practice is, but clearly the more sophisticated users have ways to game the system optimize their consumption.
But this doesn’t happen in a vacuum. It necessarily increases the likelihood that less sophisticated users will end up with (comparatively over-priced) lower-performing instances. Especially in Clouds with high heterogeneity and which have little unused capacity. It’s like coming to the fruit salad at a buffet and finding all the berries gone. I hope you like watermelon and honeydew.
Wall Street has a term for this. For people who don’t understand the system in details, who don’t have access to insider information and don’t use sophisticated trading technology: the dumb money.
Comments Off on Are you the dumb money in the Cloud?
Filed under Business, Cloud Computing, Everything, Performance, Utility computing
The enterprise Cloud battle will be an integration battle
The real threat the Cloud poses for incumbent enterprise software vendors is not the obvious one. It’s not about hosting. Sure, they would prefer if nothing changed and they could stick to shipping software and letting customers deal with installing, managing and operating it. Those were the good times.
But these days are over; Oracle, SAP and others realize it. They’re too smart to fight for a lost cause and try to stop this change (though of course they wouldn’t mind if it slowed down). They understand that they will have to host and operate their software themselves. Right now, their datacenter operations and software stacks aren’t as optimized for that model as those of native Cloud providers (at least the good ones), but they’ll get there. They have the smarts and the resources. They don’t have to re-invent it either, the skills and techniques needed will spread through the industry. They’ll also make some acquisitions to hurry things up. In the meantime, they’re probably willing to swallow the operational costs of under-optimized operations in order to prevent those of their customers most eager to move to the Cloud from defecting.
That transition, from running on the customer’s machines to running on the software vendor’s machine, while inconvenient for the vendors, is not by itself a fundamental threat.
The scary part, for enterprise software vendors transitioning to the SaaS model, is whether the enterprise application integration model will also change in the process.
[note: I include “customization” in the larger umbrella of “integration”.]
Enterprise software integration is hard and risky. Once you’ve invested in integrating your enterprise applications with one another (and/or with your partners’ applications), that integration becomes the #1 reason why you don’t want to change your applications. Or even upgrade them. That’s because the integration is an extension of the application being integrated. You can’t change the app and keep the integration. SOA didn’t change that. Both from a protocol perspective (the joys of SOAP and WS-* interoperability) and from a model perspective, SOA-type integration projects are still tightly bound to the applications they were designed for.
For all intents and purposes, the integration is subservient to the applications.
The opportunity (or risk, depending on which side you’re on) is if that model flips over as part of the move to Cloud Computing. If the integration become central and the applications become peripheral.
The integration is the application.
Which is really just pushing “the network is the computer” up the stack.
Just like cell phone operators don’t want to be a “dumb pipe”, enterprise software vendors don’t want to become a “dumb endpoint”. They want to own the glue.
That’s why Salesforce built Force.com, acquired Heroku and is now all over “enterprise social networking” (there’s no such thing as “enterprise social networking” by the way, it’s just better groupware, integrated with enterprise applications). That’s why WorkDay’s only acquisition to date, as early as 2008, was an enterprise integration vendor (CapeClear). And why Oracle, in building its public Cloud, is making sure to not just offer its applications as SaaS but also build a portfolio of integration-friendly services (“the technology services are for IT staff and software developers to build and extend business applications”).
How could this be flipped over, freeing the integration from being in the shadow of the application (and running on infrastructure provided by the application vendor)? Architecturally, this looks like a Web integration use case, as Erik Wilde posited. But that’s hard to imagine in practice, when you think of the massive amounts of data and the ever-growing requirements to extract value from it, quickly and at scale. Even if application vendors exposed good HTTP/REST APIs for their data, you don’t want to run Big Data analysis over these remote APIs.
So, how does the integration free itself from being controlled by the SaaS vendor, while retaining high-throughput and low-latency access to the data it requires? And how does the integration get high-throughput/low-latency access to data sets from different applications (by different vendors) at the same time? Well, that’s where the cliffhanger at the end of the previous blog post comes from.
Maybe the solution is to have SaaS applications run on a public Cloud. Or, in the terms used by the previous blog post, to run enterprise Solution Clouds (SaaS) on top of public Deployment Clouds (PaaS and IaaS). Two SaaS applications (by different vendors) which run on the same Deployment Cloud can then, via some level of coordination controlled by the customer, access each other’s data or let an “integration” application access both of their data sets. The customer-controlled coordination (and by “customer” here I mean the enterprise which subscribes to the SaaS apps) is two-fold: ensuring that the two SaaS applications are deployed in close proximity (in the same “Cloud zone” or whatever proximity abstraction the Deployment Cloud provider exposes); and setting appropriate access permission.
Enterprise application vendors will fight to maintain control of application integration. They will have reasons, some of them valid, supporting the case that it’s better if you use them to run your integration. But the most fundamental of these reasons, locality of the data, doesn’t have to be a blocker. That can be bridged by running on a shared public Deployment Cloud.
Remember, the integration is the application.
Will Clouds run on Clouds?
Or, more precisely, will enterprise Solution Clouds run on Deployment Clouds?
I’ve previously made the case that we shouldn’t include SaaS in the “Cloud” (rather, it’s just Web apps). Obvioulsy my guillotine didn’t cut it against the lure of Cloud-branding. Fine, then let’s agree that we have two types of Clouds: Solution Clouds and Deployment Clouds.
Solution Clouds are the same as SaaS (and I’ll use the terms interchangeably). Enterprise Solution Clouds provide common functions like HR, CRM, Financial, Collaboration, etc. Every company needs them and they are similar between companies.
Deployment Clouds are where you deploy applications. That definition covers both IaaS and PaaS, which are part of the same continuum.
You subscribe to a Solution Cloud; you deploy on a Deployment Cloud.
Considering these two types of Clouds separately doesn’t mean they’re not connected. The same providers may offer both, and they may be tightly packaged together. But they’re still different in their nature.
The reason for this little lexicological excursion is to formulate this question: will enterprise Solution Clouds run on Deployment Clouds or on their own infrastructure? Can application-centric ISVs compete, in the enterprise market, by providing a Solution Cloud on top of someone else’s Deployment Cloud? Or will the most successful enterprise Solution Clouds be run by full-stack operators?
Right now, most incumbent enterprise software vendors (Oracle, SAP…), and the Cloud-only enterprise vendors with the most adoption (SalesForce, WorkDay…) offer Cloud services by operating their own infrastructure. On the other hand, there are many successful SaaS vendors targeting smaller companies which run their operations on top of a Deployment Cloud (e.g. the Google Cloud Platform or AWS). That even seems to be the default mode of operation for these vendors. Why not enterprise vendors? Let’s look at the potential reasons for this, in order to divine if it may change in the future.
- It could be that it’s a historical accident, either because the currently successful enterprise providers necessarily started before Deployment Clouds were available (it takes time to build an enterprise Solution Cloud) or they started from existing on-premise software which didn’t lend itself to running on a Deployment Cloud. Or these SaaS providers were simply not culturally or technically ready to use Deployment Clouds.
- It could be that it’s necessary in order to provide the necessary level of security and compliance. Every enterprise SaaS vendor has a “security” whitepaper which plays up the fact that they run their own datacenter, allowing them to ensure that all the guards have a CSSLP, a fifth-degree karate black belt, a scary-looking goatee and that they follow a documented process when they brush their teeth in the morning. If that’s a reason, then it won’t change until Deployment Clouds can offer the same level of compliance (and prove it). Which is happening, BTW.
- It could be that enterprise Solution Clouds are large enough (or have vocation to become large enough) that there are little economies of scale in sharing the infrastructure with other workload.
- It could be that they can optimize the infrastructure to better serve their particular type of workload.
Any other reason? Will enterprise Solution Cloud always run on their own infrastructure? The end result probably hinges a lot on whether, once it fully moves to a Cloud delivery model, the enterprise SaaS landscape is as concentrated as the traditional enterprise application landscape was, or whether the move to Cloud opens the door to a more diverse ecosystem. The answer to this hinges, in turn, on Cloud application integration, which will be the topic of the next post.
Filed under Business, Cloud Computing, Everything, Uncategorized, Utility computing
Come for the PaaS Functional Model, stay for the Cloud Operational Model
The Functional Model of PaaS is nice, but the Operational Model matters more.
Let’s first define these terms.
The Functional Model is what the platform does for you. For example, in the case of AWS S3, it means storing objects and making them accessible via HTTP.
The Operational Model is how you consume the platform service. How you request it, how you manage it, how much it costs, basically the total sum of the responsibility you have to accept if you use the features in the Functional Model. In the case of S3, the Operational Model is made of an API/UI to manage it, a bill that comes every month, and a support channel which depends on the contract you bought.
The Operational Model is where the S (“service”) in “PaaS” takes over from the P (“platform”). The Operational Model is not always as glamorous as new runtime features. But it’s what makes Cloud Cloud. If a provider doesn’t offer the specific platform feature your application developers desire, you can work around it. Either by using a slightly-less optimal approach or by building the feature yourself on top of lower-level building blocks (as Netflix did with Cassandra on EC2 before DynamoDB was an option). But if your provider doesn’t offer an Operational Model that supports your processes and business requirements, then you’re getting a hipster’s app server, not a real PaaS. It doesn’t matter how easy it was to put together a proof-of-concept on top of that PaaS if using it in production is playing Russian roulette with your business.
If the Cloud Operational Model is so important, what defines it and what makes a good Operational Model? In short, the Operational Model must be able to integrate with the consumer’s key processes: the business processes, the development processes, the IT processes, the customer support processes, the compliance processes, etc.
To make things more concrete, here are some of the key aspects of the Operational Model.
Deployment / configuration / management
I won’t spend much time on this one, as it’s the most understood aspect. Most Clouds offer both a UI and an API to let you provision and control the artifacts (e.g. VMs, application containers, etc) via which you access the PaaS functional interface. But, while necessary, this API is only a piece of a complete operational interface.
Support
What happens when things go wrong? What support channels do you have access to? Every Cloud provider will show you a list of support options, but what’s really behind these options? And do they have the capability (technical and logistical) to handle all your issues? Do they have deep expertise in all the software components that make up their infrastructure (especially in PaaS) from top to bottom? Do they run their own datacenter or do they themselves rely on a customer support channel for any issue at that level?
SLAs
I personally think discussions around SLAs are overblown (it seems like people try to reduce the entire Cloud Operational Model to a provisioning API plus an SLA, which is comically simplistic). But SLAs are indeed part of the Operational Model.
Infrastructure change management
It’s very nice how, in a PaaS setting, the Cloud provider takes care of all change management tasks (including patching) for the infrastructure. But the fact that your Cloud provider and you agree on this doesn’t neutralize Murphy’s law any more than me wearing Michael Jordan sneakers neutralizes the law of gravity when I (try to) dunk.
In other words, if a patch or update is worth testing in a staging environment if you were to apply it on-premise, what makes you think that it’s less likely to cause a problem if it’s the Cloud provider who rolls it out? Sure, in most cases it will work just fine and you can sing the praise of “NoOps”. Until the day when things go wrong, your users are affected and you’re taken completely off-guard. Good luck debugging that problem, when you don’t even know that an infrastructure change is being rolled out and when it might not even have been rolled out uniformly across all instances of your application.
How is that handled in your provider’s Operational Model? Do you have visibility into the change schedule? Do you have the option to test your application on the new infrastructure or to at least influence in any way how and when the change gets rolled out to your instances?
Note: I’ve covered this in more details before and so has Chris Hoff.
Diagnostic
Developers have assembled a panoply of diagnostic tools (memory/thread analysis, BTM, user experience, logging, tracing…) for the on-premise model. Many of these won’t work in PaaS settings because they require a console on the local machine, or an agent, or a specific port open, or a specific feature enabled in the runtime. But the need doesn’t go away. How does your PaaS Operational Model support that process?
Customer support
You’re a customer of your Cloud, but you have customers of your own and you have to support them. Do you have the tools to react to their issues involving your Cloud-deployed application? Can you link their service requests with the related actions and data exposed via your Cloud’s operational interface?
Security / compliance
Security is part of what a Cloud provider has to worry about. The problem is, it’s a very relative concept. The issue is not what security the Cloud provider needs, it’s what security its customers need. They have requirements. They have mandates. They have regulations and audits. In short, they have their own security processes. The key question, from their perspective, is not whether the provider’s security is “good”, but whether it accommodates their own security process. Which is why security is not a “trust us” black box (I don’t think anyone has coined “NoSec” yet, but it can’t be far behind “NoOps”) but an integral part of the Cloud Operational Model.
Business management
The oft-repeated mantra is that Cloud replaces capital expenses (CapExp) with operational expenses (OpEx). There’s a lot more to it than that, but it surely contributes a lot to OpEx and that needs to be managed. How does the Cloud Operational Model support this? Are buyer-side roles clearly identified (who can create an account, who can deploy a service instance, who can manage a deployed instance, etc) and do they map well to the organizational structure of the consumer organization? Can charges be segmented and attributed to various cost centers? Can quotas be set? Can consumption/cost projections be run?
We all (at least those of us who aren’t accountants) love a great story about how some employee used a credit card to get from the Cloud something that the normal corporate process would not allow (or at too high a cost). These are fun for a while, but it’s not sustainable. This doesn’t mean organizations will not be able to take advantage of the flexibility of Cloud, but they will only be able to do it if the Cloud Operational Model provides the needed support to meet the requirements of internal control processes.
Conclusion
Some of the ways in which the Cloud Operational Model materializes can be unexpected. They can seem old-fashioned. Let’s take Amazon Web Services (AWS) as an example. When they started, ownership of AWS resources was tied to an individual user’s Amazon account. That’s a big Operational Model no-no. They’ve moved past that point. As an illustration of how the Operational Model materializes, here are some of the features that are part of Amazon’s:
- You can Fedex a drive and have Amazon load the data to S3.
- You can optimize your costs for flexible workloads via spot instances.
- The monitoring console (and API) will let you know ahead of time (when possible) which instances need to be rebooted and which will need to be terminated because they run on a soon-to-be-decommissioned server. Now you could argue that it’s a limitation of the AWS platform (lack of live migration) but that’s not the point here. Limitations exists and the role of the Operational Model is to provide the tools to handle them in an acceptable way.
- Amazon has a program to put customers in touch with qualified System Integrators.
- You can use your Amazon support channel for questions related to some 3rd party software (though I don’t know what the depth of that support is).
- To support your security and compliance requirements, AWS support multi-factor authentication and has achieved some certifications and accreditations.
- Instance status checks can help streamline your diagnostic flows.
These Operational Model features don’t generate nearly as much discussion as new Functional Model features (“oh, look, a NoSQL AWS service!”) . That’s OK. The Operational Model doesn’t seek the limelight.
Business applications are involved, in some form, in almost every activity taking place in a company. Those activities take many different forms, from a developer debugging an application to an executive examining operational expenses. The PaaS Operational Model must meet their needs.
When piracy has systemic consequences
Interesting “Planet Money” podcast on “How The U.S. Gave S&P Its Power”. I especially found that part illuminating:
But the business [of the rating agencies] started to change in the late 1960s. Instead of charging investors, the rating agencies started to take money from the issuers of the bonds. White blames the shift on the invention of “the high-speed photocopy machine.”
The ratings agencies were afraid, he says, that investors would just pass around rating information for free. So they had to start making their money from the company side. Even this seemed to work pretty well for a long time.
The short term consequences of intellectual piracy may be easy to rationalize: I can imagine that, back in the 60s, stiffing the rich and powerful credit rating agencies by using new technology (the copy machine) to duplicate a report didn’t feel very consequential and maybe even cool. But then there are long term consequences. Like, in this case, a reversal of the money flow which ended up with the issuers themselves paying the rating agencies. A fundamentally unsustainable system which, many years later, gave us credit agencies who coached their customers, the issuers, on how to craft deceptively-rated securities.
We have many examples of too much government intervention (like tax policies that encourage borrowing) setting up the conditions for a crisis, but this appears to be an example of the reverse: a lack of government intervention (to ensure that the IP of credit agencies is respected) being part of what caused a systemic problem to form.
There are similar situations being created today. I cringe when I see advertising (and gathering of personal data) becoming such a prevalent monetization model, by lack of more direct alternatives. I don’t know what form the ensuing crisis will eventually take, but it may be just as bad as the debacle of the credit rating system.
I’m not saying more IP protection is always better. The patent system is an example of the contrary. It’s a difficult balance to achieve. But looking at the money flow is a good gauge of how well the system is working. The more directly the money flows from the real producers to the real consumers, the better and the more sustainable the system is. Today, it isn’t so for credit rating agencies, nor for much of the digital economy.
Comments Off on When piracy has systemic consequences
Filed under Business, Everything, Off-topic
Backward-looking API ToS vs. forwarding-looking API usage
From the developer’s perspective, most terms of service (ToS) documents for public APIs contain only constraints and no real permission. That’s because they generally don’t come with any guarantee about the future. At best, they tell you what you were authorized to do yesterday. Since the version you’re looking at may already be outdated, it tells you nothing about what you can do now or tomorrow. That perspective is often ignored when debating a change in ToS. The new version may forbid you from doing something that was not forbidden before, but it’s not actually taking anything away from you. The only thing it would take away from you is the right to do something from now on, but you were never granted such right over that period of time.
For example, the Twitter API ToS:
“The Rules will evolve along with our ecosystem as developers continue to innovate and find new, creative ways to use the Twitter API, so please check back periodically to see the most current version.”
and more specifically
“Twitter may update or modify the Twitter API, Rules, and other terms and conditions, including the Display Guidelines, from time to time its sole discretion by posting the changes on this site or by otherwise notifying you (such notice may be via email). You acknowledge that these updates and modifications may adversely affect how your Service accesses or communicates with the Twitter API. If any change is unacceptable to you, your only recourse is to terminate this agreement by ceasing all use of the Twitter API and Twitter Content. Your continued access or use of the Twitter API or any Twitter Content will constitute binding acceptance of the change.”
Changes in the terms of service can have a major effect on consuming application, going as far as making the whole purpose of the application impossible. For example, any Twitter app is a the mercy of the next corporate strategy change decided at Twitter HQ. That can happen without any change whatsoever to the API from a technical perspective.
If building your business on a proprietary API is sharecropping, then changes in ToS are the “droit de cuissage” (a.k.a “droit du seigneur“) that comes with it. Be ready for it to be exercised at any point.
Even in the cases where the ToS contain a guarantee over time, there is often enough language to allow the provider to wiggle out of it. Case in point, the recent decommission of the Google Translate API.
In the API ToS, Google includes a generous three years deprecation window:
“If Google in its discretion chooses to cease providing the current version of the Service whether through discontinuation of the Service or by upgrading the Service to a newer version, the current version of the Service will be deprecated and become a Deprecated Version of the Service. Google will issue an announcement if the current version of the Service will be deprecated. For a period of 3 years after an announcement (the “Deprecation Period”), Google will use commercially reasonable efforts to continue to operate the Deprecated Version of the Service and to respond to problems with the Deprecated Version of the Service deemed by Google in its discretion to be critical. During the Deprecation Period, no new features will be added to the Deprecated Version of the Service.”
But further down, Google reserves the right to do away with the Deprecation Period for several reasons, among which:
“- providing the Deprecated Version of the Service could create a substantial economic burden on Google as determined by Google in its reasonable good faith judgment; or
– providing the Deprecated Version of the Service could create a security risk or material technical burden upon Google as determined by Google in its reasonable good faith judgment.”
A “substantial economic burden” or a “material technical burden”. I am not a lawyer, but good luck going to court against Google arguing that maintaining the API doesn’t provide any such burden if Google claims it does (if I was a Google lawyer, I’d ask “if there’s no such burden, why don’t you provide it yourself?”).
And that’s exactly what Google is claiming in the case of the Translate API. There’s a reason why the words “substantial economic burden” are included in this statement at the very top of the home page for the Google Translate API.
“Important: The Google Translate API has been officially deprecated as of May 26, 2011. Due to the substantial economic burden caused by extensive abuse, the number of requests you may make per day will be limited and the API will be shut off completely on December 1, 2011. For website translations, we encourage you to use the Google Translate Element.”
[For more information about Google’s translation services and what might really be behind this change, I recommend reading this interesting analysis. Whether or not the author is guessing right, it’s an interesting perspective on how the marriage between Search and Advertising turns into a love triangle (with Translation as the third party) when you take a worldwide perspective.]
Protection against such changes (changes in ToS or the API going away entirely) would be a nice value-add for the companies that offer services around managing API usage. I vaguely remember an earlier announcement about Apigee providing a way to invoke the Twitter API that was sheltered from Twitter’s throttling (presumably via some agreement between Apigee and Twitter). Maybe Apigee can also negotiate long-term bidirectional ToS agreements with API providers on behalf of its customers. If I was building a business on top of a third-party service like Twitter, I’d probably value that kind of guarantee even more than the cool technical tools Apigee provides around API usage.
What’s more important in an API? Whether it’s REST or SOAP or whether you can count on using it for some time in the future?
Comments Off on Backward-looking API ToS vs. forwarding-looking API usage
Filed under API, Business, Everything, Google, Protocols
“Toyota Friend”: It’s cool! It’s social! It’s cloud! It’s… spam.
Michael Coté has it right: “all roads lead to better junk mail.”
We can take “road” literally in this case since Toyota has teamed up with Salesforce.com to “build Toyota Friend social network for Toyota customers and their cars“.
If you’re tired of “I am getting a fat-free decaf latte at Starbucks” FourSquare messages, wait until you start receiving “my car is getting a lead-free 95-octane pure arabica gas refill at Chevron”. That’s because Toyota owners will get to “choose to extend their communication to family, friends, and others through public social networks such as Twitter and Facebook“.
Leaving “family and friends” aside (they will beg you to), the main goal of this social network is to connect “Toyota customers with their cars, their dealership, and with Toyota”. And what for purpose? The press release has an example:
For example, if an EV or PHV is running low on battery power, Toyota Friend would notify the driver to re-charge in the form of a “tweet”-like alert.
That’s pretty handy, but every car I’ve ever owned has sent me a “tweet-like” alert in the form of a light on the dashboard when I got low on fuel.
Toyota’s partner, Salesforce, also shares its excitement about this (they bring the Cloud angle), and offers another example of its benefits:
Would you like to know if your dealer’s service department has a big empty space on its calendar tomorrow morning, and is willing to offer you a sizable discount on routine service if you’ll bring the car in then instead of waiting another 100 miles?
Ten years ago, the fancy way to justify spamming people was to say that you offered “personalization”. Look at this old advertisement (which lists Toyota as a customer) about how “personalization” is the way to better connect with customers and get them to buy more. Today, we’ve replaced “personalization” with “social media” but it’s the exact same value proposition to the company (coupled with a shiny new way to feed it to its customers).
BTW, the company behind the advertisement? Broadvision. Remember Broadvision? Internet bubble darling, its share price hit over $20,000 (split-adjusted to today). According to the ad above, it was at the time “the world’s second leading e-commerce vendor in terms of licensing revenues, just behind Netscape and ahead of Oracle, IBM, and even Microsoft” and “the Internet commerce firm listed in Bloomberg’s Top 100 Stocks”. Today, it’s considered a Micro-cap stock. Which reminds me, I still haven’t gotten around to buying some LinkedIn…
Notice who’s missing from the list of people you’ll connect to using Toyota’s social network? Independent repair shops and owners forums (outside Toyota). Now, if this social network was used to let me and third-party shops retrieve all diagnostic information about my car and all related knowledge from Toyota and online forums that would be valuable. But that’s the last thing on earth Toyota wants.
A while ago, a strange-looking icon lit up on the dashboard of my Prius. Looking at it, I had no idea what it meant. A Web search (which did not land on Toyota’s site of course) told me it indicated low tire pressure (I had a slow leak). Even then, I had no idea which tire it was. Now at that point it’s probably a good idea to check all four of them anyway, but you’d think that with two LCD screens available in the car they’d have a way to show you precise and accurate messages rather than cryptic icons. It’s pretty clear that the whole thing is designed with the one and only goal of making you go to your friendly Toyota dealership.
Which is why, without having seen this “Toyota Friend” network in action, I am pretty sure I know it will be just another way to spam me and try to scare me away from bringing my car anywhere but to Toyota.
Dear Toyota, I don’t want “social”, I want “open”.
In the meantime, and since you care about my family, please fix the problem that is infuriating my Japanese-American father in law: that the voice recognition in his Japan-made car doesn’t understand his accented English. Thanks.
Comments Off on “Toyota Friend”: It’s cool! It’s social! It’s cloud! It’s… spam.
Filed under Automation, Business, Cloud Computing, Everything, Off-topic
Cloud management is to traditional IT management what spreadsheets are to calculators
It’s all in the title of the post. An elevator pitch short enough for a 1-story ride. A description for business people. People who don’t want to hear about models, virtualization, blueprints and devops. But people who also don’t want to be insulted with vague claims about “business/IT alignment” and “agility”.
The focus is on repeatability. Repeatability saves work and allows new approaches. I’ve found spreadsheets (and “super-spreadsheets”, i.e. more advanced BI tools) to be a good analogy for business people. Compared to analysts furiously operating calculators, spreadsheets save work and prevent errors. But beyond these cost savings, they allow you to do things you wouldn’t even try to do without them. It’s not just the same process, done faster and cheaper. It’s a more mature way of running your business.
Same with the “Cloud” style of IT management.
Can I get a price check on this AMI?
I almost titled this entry “Cloud + Tivoli = $” in reference to the previous one (“Cloud + proprietary software = ♥”). In that earlier entry, I described the opportunity for Cloud providers to benefit themselves, their customers and software vendors by drastically reducing the frictions involved in using proprietary software (rather than open source software). The example I used was Windows EC2 instances. But it’s not the best example because there is a very tight relationship between Amazon and Microsoft on this. In many ways, these Windows instances are “hard-coded” in EC2: they have a special credential retrieval mechanism, their price appears in the main EC2 price list, etc. This cannot scale as a generic Amazon-mediated payment service for many software vendors.
Rather than the special case of Windows instances, the more interesting situation to look at is the availability of vendor-provided EC2 instances at a higher price. So I went to look a bit more into this, and I came out… very confused and $20 poorer.
Earlier in the week, I had noticed an announcement of IBM Tivoli on EC2 that explained that “the hourly price for Tivoli on EC2 includes an IBM license”. This seemed like a perfect place for me to start. My first question was “how much does it cost”? The blog entry doesn’t say. It links to a Tivoli on EC2 FAQ on the IBM site, which doesn’t say either (apparently IBM’s target customers work in recession-proof industries and do not “frequently ask” about prices). I then followed the link to the overall IBM and AWS FAQ but it just states that “charges will be announced by Amazon Web Services in the coming months”. Both FAQs explain how to use your traditional IBM license on EC2, but that’s not what I am after. At this point, I feel like a third-world tourist who entered a high-end jewelry store in Paris where no price is displayed. Call me plebeian, but I am more accustomed to Target-like stores with price-check scanners in the aisles…
I hypothesized that the AWS console might show me the price when I select the Tivoli AMIs. But no such luck. Tired of searching, and since I was already in the console, I figured I’d just launch an instance and see the hourly cost in my account usage. Since it comes in three versions (depending on how many targets you want Tivoli to manage), I launched one of each. Additionally, for one of them I launched instances of two different sizes so I can verify that the price difference is equal to the base EC2 price difference between such instance sizes. Here is what I got:

Of course, by the time my account usage page was updated (it took a few hours) I had found the price list which in retrospect wasn’t that hard to find (from Amazon, not IBM).
So maybe I am not the brightest droplet in the cloud, but for 20 bucks I consider that at least I bought the right to make a point: these prices should not be just on some web page. They should be accessible at the time of launch, in the console. And also in the EC2 API, so that the various EC2 tools can retrieve them. Whether it’s just for human display or to use as part of some automation logic, this should be available in an authoritative manner, without the need to scrape a page.
The other thing that bothers me is the need to decide upfront whether I want to launch a Tivoli instance to manage 50 virtual cores, 200 virtual cores or 600 virtual cores. That feels very inelastic for an EC2 deployment. I want to be charged for the actual number of virtual cores I am managing at any point in time. I realize the difficulty in metering this way (the need for Tivoli to report this to AWS, the issue of trust…) but hopefully it will eventually get there.
While I am talking about future improvements, another limitation is that there can currently only be one vendor per AMI. What if someone wants to write an application that runs on top of Oracle Middleware and package this as a paid AMI? It would be nice if Amazon eventually allowed the price of the instance to be split three-ways (Amazon, Oracle, application vendor).
In any case, now you know why this investigation left me poorer. The confused part comes from the fact that I had earlier experimented with Amazon Paid AMIs and it was an entirely different experience. Better in some ways: you get a clear price list upfront such as this.

But not as good in other ways: you have to purchase the paid AMI in a way that it is somewhat disconnected from the launch of the instance. And for some reason you paid for this directly out of your credit card as opposed to it going to your AWS usage account along with all your other charges. I would expect that many customers will use these paid AMIs are part of a larger EC2 deployment and as such it seems awkward to have it billed separately.
But overall, it’s the disconnect between the two that the confuses me. Are there two different types of paid AMIs (three if you include the Windows EC2 instances)? What am I missing?
The next step in my investigation should probably be to create an AMI and set a price on it, so I get the vendor’s view in addition to the consumer’s view. And maybe I can earn my $20 back in the process…
Filed under Amazon, Application Mgmt, Business, Cloud Computing, Everything, IBM, IT Systems Mgmt, Utility computing
Cloud + proprietary software = ♥
When I left HP for Oracle, in the summer of 2007, a friend made the argument that Cloud Computing (I think we were still saying “Utility Computing” at the time) would be the death of proprietary software.
There was a lot to support this view. EC2 was one year old and its usage was overwhelmingly based on open source software (OSS). For proprietary software, there was no clear understanding of how licensing terms applied to Cloud deployments. Not only would most sales reps not know the answer, back then they probably wouldn’t have comprehended the question.
Two and a half years later… well it doesn’t look all that different at first blush. EC2 seems to still be a largely OSS-dominated playground. Especially since the most obvious (though not necessarily the most accurate) measure is to peruse the description/content of public AMIs. They are (predictably since you can’t generally redistribute proprietary software) almost entirely OSS-based, with the exception of the public AMIs provided by software vendors themselves (Oracle, IBM…).
And yet the situation has improved for usage of proprietary software in the Cloud. Most software vendors have embraced Cloud deployments and clarified licensing issues (taking the example of Oracle, here is its Cloud Computing Center page, an overview of the licensing policy for Cloud deployments and the AWS/Oracle partnership page to encourage the use of Oracle software on EC2; none of this existed in 2007).
But these can be called reactive adaptations. At best (depending on the variability of your load and whether you use an Unlimited License Agreement), these moves have brought the “proprietary vs. OSS” debate in the Cloud back to the same parameters as for on-premise deployments. They have simply corrected the initial challenge of not even knowing how to license proprietary software for Cloud deployments.
But it’s not stopping here. What we are seeing is some of the parameters for the “proprietary vs. OSS” debate become more friendly towards proprietary software in the Cloud than on-premise. I am referring to the emergence of EC2 instances for which the software licenses are included in the per-hour rate for server instances. This pretty much removes license management as a concern altogether. The main example is Windows EC2 instances. As a user, you don’t have to deal with any Windows license consideration. You just request a machine and use it. Which of course doesn’t mean you are not paying for Windows. These Windows instances are more expensive than comparable Linux instances (e.g. $0.34 versus $0.48 per hour in the case of a “standard/large” instance) and Amazon takes care of paying Microsoft.
The removal of license management as a concern may not make a big difference to large corporations that have an Unlimited License Agreement, but for smaller companies it may take a chunk out of the reasons to use open source software. Not only do you not have to track license usage (and renewal), you never have to spend time with a sales rep. You don’t have to ask yourself at what point in your beta program you’ve moved from a legitimate use of the (often free) development license to a situation in which you need a production license. Including the software license directly in the cost of the base Cloud resource (e.g. the virtual machine instance) makes planning (and auto-scaling) easier: you use the same algorithm as in the “free license” situation, just with a different per hour cost. The trade-off becomes quantitative rather than qualitative. You can trade a given software stack against a faster CPU or more memory or more storage, depending on which combination serves your needs better. It doesn’t matter if the value you get from the instance comes from the software in the image or the hardware. This moves IaaS closer to PaaS (force.com doesn’t itemize your bill between hardware cost and software cost). Anything that makes IaaS more like PaaS is good for IaaS.
From an earlier post, about virtual appliances:
As with all things computer-related, the issue is going to get blurrier and then irrelevant . The great thing about software is that there is no solid line. In this case, we will eventually get more customized appliances (via appliance builders or model-driven appliance generation) blurring the line between installed software and appliance-based software.
I was referring to a blurring line in terms of how software is managed, but it’s also true in terms of how it is licensed.
There are of course many other reasons (than license management) why people use open source software rather than proprietary. The most obvious being the cost of the license (which, as we have seen, doesn’t go away but just gets incorporated in the base Cloud instance rate). Or they may simply prefer a given open source product independently of any licensing aspect. Some need access to the underlying code, to customize/improve it for their purpose. Or they may be leery of depending on one entity for the long-term viability of their platform. There may even be some who suspect any software that they don’t examine/compile themselves to contain backdoors (though these people are presumably not candidates for Cloud deployments in he first place). Etc. These reasons remain pretty much unchanged in the Cloud. But, anecdotally at least, removing license management concerns from both manual and automated tasks is a big improvement.
If Cloud providers get it right (which would require being smarter than wireless service providers, a low bar) and software vendors play ball, the “proprietary vs. OSS” debate may become more favorable to proprietary software in the Cloud than it is on-premise. For the benefit of customers, software vendors and Cloud providers. Hopefully Amazon will succeed where telcos mostly failed, in providing a convenient application metering/billing service for 3rd-party software offered on top of their infrastructural services (without otherwise getting in the way). Anybody remembers the Minitel? Today we’d call that a “Terminal as a Service” offering and if it did one thing well (beyond displaying green characters) it was billing. Which reminds me, I probably still have one in my parent’s basement.
[Note: every page of this blog mentions, at the bottom, that “the statements and opinions expressed here are my own and do not necessarily represent those of Oracle Corporation” but in this case I will repeat it here, in the body of the post.]
[UPDATED 2009/12/29: The Register seems to agree. In fact, they come close to paraphrasing this blog entry:
“It’s proprietary applications offered by enterprise mainstays such as Oracle, IBM, and other big vendors that may turn out to be the big winners. The big vendors simply manipulated and corrected their licensing strategies to offer their applications in an on-demand or subscription manner.
Amazonian middlemen
AWS, for example, now offers EC2 instances for which the software licenses are included in the per-hour rate for server instances. This means that users who want to run Windows applications don’t have to deal with dreaded Windows licensing – instead, they simply request a machine and use it while Amazon deals with paying Microsoft.”]
[UPDATED 2010/1/25: I think this “Cloud as Monetization Strategy for Open Source” post by Geva Perry (based on an earlier post by Savio Rodrigues ) confirms that in the Cloud the line between open source and proprietary software is thinning.]
[UPDATED 2010/11/12: Related and interesting post on the AWS blog: Cloud Licensing Models That Exist Today]
Cloud catalog catalyst or cloud catalog cataclysm?
Like librarians, we IT wonks tend to like things cataloged. To date, the last instance of this has been SOA governance and its various registries and repositories. With UDDI limping along as some kind of organizing standard for the effort. One issue I have with UDDI is that its technical awkwardness is preventing us from learning from its failure to realize its ambitious goals (“e-business heaven”). It would be too easy to attribute the UDDI disappointment to UDDI. Rather, it should be laid at the feet of unreasonable initial expectations.
The SOA governance saga is still ongoing, now away from the spotlight and mostly from an implementation perspective rather than a standard perspective (by the way, what’s up with GIF?). Instead, the spotlight has turned to Cloud computing and that’s what we are supposedly going to control through cataloging next.
Earlier this year, I commented on the release of an ITSM catalog product for Cloud computing (though I was addressing the convergence of ITSM and Cloud computing more than catalogs per se).
More recently, Lori MacVittie related SOA governance to the need for Cloud catalogs. She makes some good points, but I also see some familiar-looking “irrational exuberance”. The idea of dynamically discovering and invoking a Cloud service reminds me too much of the initial “yellow pages” scenarios for UDDI (which quickly got dropped in favor of a more modest internal governance focus).
I am not convinced by the reason Lori gives for why things are different this time around (“one of the interesting things virtualization brings to the table that SOA did not is the ability to abstract management of services”). She argues that SOA governance only gave you access to the operational WSDL of a Web service, while Cloud catalogs will give you access to their management API. But if your service is an IT service, then your so-called management API (launch/configure/control VMs) is really its operational interface. The real management interface is the one Amazon uses under the cover and they are not going to expose it to you anymore than your bank is going to expose its application server administration console to you (if they do, move your money somewhere else before someone does it for you).
After all, isn’t SOA governance pretty close to a SaaS catalog which is itself a small part of the overall Cloud (IaaS+PaaS+SaaS) catalog question? If we still haven’t succeeded in the smaller scope, what are the odds of striking gold quickly in the larger effort?
Some analysts take a more pragmatic view, involving active brokers rather than simply a new DNS record type. I am doubtful about these brokers (0.2 probability, as Gartner would put it) but at least this moves the question onto business terms (leverage, control) rather than technical terms. Which is where the battle will be fought.
When it comes to Cloud catalogs, I think they are needed (if only for the categorization of Cloud services that they require) but will only play a supporting role, if any, in any move towards dynamic Cloud provisioning. As with SOA governance it’s as an internal tool, supported by strong processes, that they will be most useful.
Throughout human history, catalogs have been substitutes for control more often than instruments of control. Think of astronomy, zoology and… nephology for example. What kind will IT Cloud catalogs be?
A small step for SCA, a giant leap for BSM
In a very short post, Khanderao Kand describes how configuration properties for BPEL processes in Oracle SOA Suite 11G are attached to SCA components. Here is the example he provides:
<component name="myBPELServiecComponent"> ... <property name="bpel.config.inMemoryOptimization">true</property> </component>
It doesn’t look like much. But it’s an major step for application-driven IT management (and eventually BSM).
Take a SCA component. Follow the SCA-defined component-to-composite and service-to-reference relationships upwards and eventually you’ll get to top level application services that have a decent chance of mapping well to business-relevant activities (e.g. order processing). Which means that the metrics of these services (e.g. availability, response time) are likely to be meaningful and important to the line of business. Follow the same SCA relationships downward and you’ll end up (in a SCA-based infrastructure like Oracle SOA Suite 11G), with target components that are meaningful to the IT administrator. Which means that their metrics and configuration settings (like “inMemoryOptimization”) are tracked and controlled by IT. You now have a direct string of connections between this configuration setting and a business relevant metric. You can navigate the connection in both directions: downward/reactive (“my service just went down, what changed in the infrastructure”) versus upward/proactive (“my service is always slow, what can I do to optimize the execution”).
Of course these examples are over-simplistic (and the title of this post is a bit too lyrical, on account of this). Following these SCA relationships in brute-force fashion will yield tens of thousands of low-level configuration settings for any top-level service, with widely differing importance and impact (not to mention that they interact). You need rules to make sense of this. Plus, configuration-based models are a complement to runtime transaction discovery, not a replacement (unless your model of the application includes every single line of code). But it’s not that often that you can see a missing link snap into place that clearly.
What this shows is the emergence of a common set of entities between the developer’s model and the IT admin model. And if the application was developed correctly, some of the entities in the developer’s model correspond to entities in the mental model of the application user and the line of business manager. SCA is the skeleton for this. Attaching configuration to SCA components puts muscle on the bone.
The road to BSM is paved with small improvements in the semantic alignment between IT infrastructure and application services. A couple of years ago, I tried to explain why SCA is very relevant for IT management. Now we can see it.
Filed under Application Mgmt, BPEL, BSM, Business, Business Process, Everything, IT Systems Mgmt, Mgmt integration, Middleware, Modeling, Oracle, SCA, Standards
Hyperic joins SpringSource
SpringSource’s Rod Johnson tells us today that his company just bought Hyperic. The press release is a bit more specific, announcing that SpringSource acquired “substantially all of the assets of Hyperic”, which sounds different from acquiring the company itself. Maybe not for SpringSource customers, but possibly for current Hyperic customers (and investors). Acquiring the assets of an open source company may sound like a bit of an oxymoron (though I understand it’s not just about the source code), but Hyperic is what’s called an “open core” company, which means not all the code is open source (see Tarus’ take on it). But the main difference between this and forking might be that you are getting the key employees; who are nice enough with their investors do to it in an orderly way.
Anyway, this is not a business or HR blog, it’s about the technology. And on that front, this looks like an interesting way for SpringSource to expand their monitoring from just the application down into some parts of the infrastructure, at least to some extent. SpringSource’s AMS (Application Management Suite) was already based on Hyperic, so the integration headaches should be minimal. And Hyperic has been doing some Cloud monitoring work too (see this podcast if you want to learn more about it), which if nothing else is PR gold these days (I am not saying it’s just that, but it is that for sure).
As a side note, it is ironic that Hyperic (which started inside Covalent until Javier Soltero spun it off and became its CEO) is now reunited with its mothership (SpringSource acquired Covalent last year).
I am a big proponent of management capabilities in application infrastructure. I applauded Rod Johnson for writing something along the same line last year and I am pleased to see him really push this approach with this acquisition.
Here are the questions that come to my mind when I read about this deal (keep in mind that this is competition from my perspective, so feel free to “question my questions” as you read):
I was going to ask whether this acquisition means that Hyperic users who don’t care for Spring are going to see diminishing value as the product becomes more tied to Spring. But if you look at what Hyperic gives you on the resources it manages, it’s mainly a list of metrics and a few control operations. These will still be there because they’ll be needed for the Spring-centric view anyway. It would be more of a question if Hyperic had advanced discovery features (e.g. examine all the config files of the managed resources and extract infrastructure topology from them). I would wonder if these would still be maintained/improved for non-Spring middleware. But again, not an issue here since I don’t think there is much of this in Hyperic today. And since presumably SpringSource made the acquisition in part to cover more resources types in their management offering (Rod talks about DB and VM management in his post), the list of supported infrastructure elements (OS, DB, VM, network…) will presumably grow rather than shrink. What may be trimmed down eventually is the list of application runtimes currently supported. If you’re a Hyperic/Coldfusion user you should probably attend the upcoming webcast to hear about the plans.
Still on the topic of Hyperic’s monitoring-only capabilities, it means that if Rod Johnson really wants to provide everything for Java developers to put “applications into production without the mediation of operations”, as he says, then he should keep his checkbook open (as a side note, if a developer puts “applications into production” then s/he doesn’t bypass operations but rather becomes operations; you may not think of yourself as one, but if you’re the one who gets called when the application crashes then you are in “operations”). SpringSource is still a long way from offering the complete picture. Here are my guesses for the management features on Rod’s grocery list:
- configuration management -many potential acquisition candidates
- in depth database management (going beyond the “you want metrics? we’ve got metrics!” approach to DB management) – fewer candidates
As far as in-house developement, I would expect this acquisition to first yield some auto-discovery of application (and infrastructure) topology in a Spring environment. Then they’ll have to decide if they want to double-down on Cloud support and build/buy more automation features or rather focus on application-centric management and join the fray of BTM / transaction tracing. Doing both at the same time would be very ambitious. This Register article seems to imply the former (Cloud) but my guess is that SpringSource will make the smart choice of focusing on the latter (application-centric management). I see in the Register that, “Peter Cooper-Ellis, SpringSource’s senior vice president of engineering and product management called management of the cloud and virtualized datacenters a strategic driver for the deal”. But this sounds more like telling a buzzword-hungry reporter what he wants to hear rather than actual strategy to me. We’ll see. I hope this acquisition and its follow-through will help move the industry in the right direction of application-centric management, something that will take more than one company.
[UPDATED 2009/5/7: A nice article on the acquisition by Charles Humble at InfoQ. Though I have to take issue with the assertion that “many aspects of monitoring that are essential in a data centre, such as OS and network monitoring, are irrelevant in the context of the cloud”.]
[UPDATED 2009/6/23: Via Coté, an announcement that shows that the Cloud angle might have more post-aquisition juice than I expected. Unless this thing coasted on momentum alone.]
Exploring “IT management in a changing IT world”
The tagline for this blog is “IT management in a changing IT world”. Of course nobody but their authors care about blog taglines. Still, in the unlikely event that I am asked to expand on the “changing IT world” part I would do it as follows.
The changes currently at work in the IT world can be organized along three axis:
- IT infrastructure and management
- Application development and delivery
- Business and regulation
Each of these categories is ridiculously large. It’s only through the prism of the relationships between them that they provide any value. Think about three balls linked by coil springs.

If you give one of these balls a shake, you will start a hard-to-predict dance between them. This is similar to how the three domains above relate to one another. Changes in one (say a new focus on regulatory compliance in the “business” area, the emergence of virtualization technology in the “infrastructure” area or the appearance of Web 2.0 applications in the “application” area) start a complex movement involving all three. It takes a while to achieve a new equilibrium (and in practice it is never achieved since changes occur too often, adding stimulus to an already excited system). For a visual illustration, see this little YouTube video (but imagine that the three balls are arranged in a triangle rather than linearly and that every so often one of them gets pulled in a random direction).
This is not new of course. There have been changes in these three areas for as long as IT has existed (starting before it was called IT) and they have always driven changes in how IT is managed. To some extent they also have always influenced one another. The “new” part is that the connections are a lot tighter now, that the springs have a much higher force constant (the “k” in “F=-kx”). So here is my attempt at mapping today’s hot buzzwords on a map organized along these areas.

Before you ask: yes of course I have a very rigorous methodology, based on very precise quantitative data, to establish with certainty the exact x, y and z coordinates of each label. Buzzword topology is a precise science.
You may notice that the buzziest buzzword (at least currently), “Cloud”, does not appear on the map. It’s because it buzzes so much that it would be all over it, engulfing what currently appears as “virtualization”, “datacenter automation”, “Iaas”, “PaaS”, “SaaS” and “opex/capex”. There are two main parts in the “Cloud” buzzword: the “Technical Cloud” and the “Business Cloud”. The “Technical Cloud” is where we take virtualization and standardization (of machines, networks and application infrastructure) and turn that mind-boggling complexity into a manageable system that can be programmed to deliver applications (Cisco recently called it “Unified Computing”; HP, IBM and others have been trying to describe and brand it for a long time). Building on these technical capabilities comes the second part of “Cloud”, the “Business Cloud”. It is the ability to use infrastructure owned by a third party (presumably one able to leverage economies of scale) and all the possibilities this opens in the business realm. That’s what “Cloud” started as, back when it was known as “Utility Computing” and before it was applied to everything under the sun. A recent illustration of the relationship between the “Technical Cloud” and the “Business Cloud” is the introduction of vCloud by VMWare (their vision includes using VMotion technology, a piece of the “Technical Cloud”, not just to move machines between neighboring hypervisors but between organizations, enabling the “Business Cloud”). Anyway, that’s why “Cloud” it’s not on the map. It is actually all over it.
The system displayed on the map is vibrating very intensely right now, and I don’t see this changing anytime soon. Just for fun, here are candidates for future boxes on the map:
- In the “IT infrastructure and management” category, maybe one day we’ll get to real metadata-driven management integration across the stack (as opposed to the more limited “application modeling” area listed above), whether through RDF or not.
- In the “application development and delivery” category, maybe Doug Purdy’s vision “to make everyone a programmer (even if they don’t know it)” will be realized, whether through Oslo or not.
- In the “business and regulation” category, maybe one day corporations will actually start caring about the customer data they are entrusted to (but only if mishandling it finally costs them more than “sorry about that, here is a one year credit monitoring subscription now go away”).
In summary, the evolution of IT management is driven not only by changes in IT technology but also by changes in two other fields (“application development and delivery” and “business and regulation”) with which it is tightly connected. Both of these fields are also in a very dynamic state. And they also influence one another, resulting in a complex three-way dance. You can’t understand the trajectory and moves of one dancer without seeing the others.
That’s what I mean by “IT management in a changing IT world”. Thanks for asking.
[UPDATED 2009/6/25: For more on the “technical cloud” versus “business cloud”, go read Neil Ward-Dutton’s nice explanation. He actually breaks down the “business cloud” in two (separating the economic aspect from the strategic aspect).]
The Hippocratic Oath for IT management systems
The first feature of any IT management application should be “primum non nocere”, or in English “first, do no harm”. Your IT management application should not ever:
- crash the system it manages
- materially degrade its performance
- introduce security vulnerabilities to the system
It’s appropriate that the “primum non nocere” expression comes from a medical background, since IT management software acts, to a large extent, like the doctor of the datacenter. In that spirit, I wondered whether the Hippocratic Oath could also provide good guidelines to those designing IT management software.
Turns out, the original oath hasn’t aged so well (though it cannot hurt to remind IT consultants not to have sex with the IT staff of their customers or attempt to remove kidney stones on them).
On the other hand, there is a modern version (written by Louis Lasagna in 1964) that maps quite well to our domain. Here it is, with each paragraph followed (in bold font) by its translation for IT management. Just food for thoughts.
I swear to fulfill, to the best of my ability and judgment, this covenant:
I will respect the hard-won scientific gains of those physicians in whose steps I walk, and gladly share such knowledge as is mine with those who are to follow.
Follow standards, publish configuration best practices in your domain of expertise, contribute to open source projects.
I will apply, for the benefit of the sick, all measures [that] are required, avoiding those twin traps of overtreatment and therapeutic nihilism.
Provide useful features that fully address customer needs. Not a superficial product, but not a boatload of useless features and meaningless metrics either.
I will remember that there is art to medicine as well as science, and that warmth, sympathy, and understanding may outweigh the surgeon’s knife or the chemist’s drug.
Good technology is important, but so are support, documentation and user interface.
I will not be ashamed to say “I know not,” nor will I fail to call in my colleagues when the skills of another are needed for a patient’s recovery.
Don’t push “consulting engagements” to stretch your application to deliver features it is not designed for. Instead, integrate with products that perform the function well.
I will respect the privacy of my patients, for their problems are not disclosed to me that the world may know. Most especially must I tread with care in matters of life and death. If it is given me to save a life, all thanks. But it may also be within my power to take a life; this awesome responsibility must be faced with great humbleness and awareness of my own frailty. Above all, I must not play at God.
Implement roles, permissions and auditing. Be very careful not to inadvertently crash, slow or compromise the target system. Keep in mind, in your design, that you and your developers are fallible.
I will remember that I do not treat a fever chart, a cancerous growth, but a sick human being, whose illness may affect the person’s family and economic stability. My responsibility includes these related problems, if I am to care adequately for the sick.
You are not managing just a server, a JVM or a database. Considers the entire IT system and the business value it delivers.
I will prevent disease whenever I can, for prevention is preferable to cure.
Proactively monitor the system, detect problems before they impact the system and, when possible, automate resolution.
I will remember that I remain a member of society, with special obligations to all my fellow human beings, those sound of mind and body as well as the infirm.
Don’t cheat, or abuse your position. Be honest and decent with customers, partners and competitors.
If I do not violate this oath, may I enjoy life and art, respected while I live and remembered with affection thereafter. May I always act so as to preserve the finest traditions of my calling and may I long experience the joy of healing those who seek my help.
If you do all this, customers will keep buying from you and may even like you.
Filed under Business, Everything, IT Systems Mgmt
Dear Microsoft, here is my $0.25 Windows license fee for the month
Pricing is now available for Windows instances on Amazon EC2. More than the technical availability of Windows AMIs, the fact that you get pay your Windows license fee based on usage is a major change. This is where Microsoft’s announcement goes beyond Oracle’s EC2 announcement at Oracle Open World.
But why stop at EC2 instances? If I can do it there, why can’t I do it at home? Considering how rarely my home desktop is booted to Windows, I would love to pay my Windows license in a metered way. It would basically be limited to time spent editing video and participating in family Skype videconference (at least until I manage to get Skype full screen video to work on Ubuntu).
After all, why only Amazon and not other Cloud providers. And when this happens, I think I may become a cloud provider myself. It would be a small-scale operation. One physical CPU (my desktop). And one user (me). I would meter my usage and dutifully pay Microsoft every month based on the number of hours during which I was running Windows.
How much would that be? Well, a Linux Small Standard Image EC2 instance (the closest thing to my aging desktop) costs $0.10 per hour. The Windows version costs $0.125 per hour, so the Windows license on this machine costs 2.5 cents per hour. On a given month, I don’t use it for more than 10 hours (edit/render one DVD plus a few hours on Skype). That’s 25 cents. Does Microsoft take Paypal? Is the Microsoft tax about to get more progressive?
It will be interesting to see how Microsoft manages to be flexible on server OS licensing (where it has plenty of competition) and while keeping its highly profitable (and unfairly front-loaded and restrictive) desktop OS licensing intact.
[UPDATED 2009/1/19: What do you know, here is a Microsoft patent for a “Metered Pay-As-You-Go Computing Experience”, found through this article.]
Filed under Amazon, Business, Everything, Microsoft, Utility computing
Animoto is no infrastructure flexibility benchmark
I have nothing against Animoto. From what I know about them (mostly from John’s podcast with Brad Jefferson) they built their system, using EC2, in a very smart way.
But I do have something against their story being used to set the benchmark for infrastructure flexibility. For those who haven’t heard it five times already, the summary of “their story” is ramping up from 50 to 5000 machines in a week (according to the podcast). Or from 50 to 3500 (according to the this AWS blog entry). Whatever. If I auto-generate my load (which is mostly what they did when they decided to auto-create a custom video for each new user) I too can create the need for a thousands of machines.
This was probably a good business decision for Animoto. They got plenty of visibility at a low cost. Plus the extra publicity from being an EC2 success story (I for one would never have heard of them through their other channels). Good for them. Good for Amazon who made it possible. And who got a poster child out of it. Good for the facebookers who got to waste another 30 seconds of their time straining their eyes. Everyone is happy, no animal got hurt in the process, hurray.
That’s all good but it doesn’t mean that from now on any utility computing solution needs to support ramping up by a factor of 100 in a week. What if Animoto had been STD’ed (slashdoted, technoratied and dugg) at the same time as the Facebook burst, resulting in the need for 50,000 servers? Would 1,000 X be the new benchmark? What if a few of the sites that target the “lonely guy” demographic decided to use Animoto for… ok let’s not got there.
There are three types of user requirements. The Animoto use case is clearly not in the first category but I am not convinced it’s in the third one either.
- The “pulled out of thin air” requirements that someone makes up on the fly to justify a feature that they’ve already decided needs to be there. Most frequently encountered in standards working groups.
- The “it happened” requirements that assumes that because something happened sometimes somewhere it needs to be supported all the time everywhere.
- The “it makes business sense” requirements that include a cost-value analysis. The kind that comes not from asking “would you like this” to a customer but rather “how much more would you pay for this” or “what other feature would you trade for this”.
When cloud computing succeeds (i.e. when you stop hearing about it all the time and, hopefully, we go back to calling it “utility computing”), it will be because the third category of requirements will have been identified and met. Best exemplified by the attitude of Tarus (from OpenNMS) in the latest Redmonk podcast (paraphrased): sure we’ll customize OpenNMS for cloud environments; as soon as someone pays us to do it.
Filed under Amazon, Business, CMDB Federation, Everything, Mgmt integration, Specs, Tech, Utility computing
Moving towards utility/cloud computing standards?
This Forbes article (via John) channels 3Tera’s Bert Armijo’s call for standardization of utility computing. He calls it “Open Cloud” and it would “allow a company’s IT systems to be shared between different cloud computing services and moved freely between them“. Bert talks a bit more about it on his blog and, while he doesn’t reference the Forbes interview (too modest?), he points to Cloudscape as the vision.
A few early thoughts on all this:
- No offense to Forbes but I wouldn’t read too much into the article. Being Forbes, they get quotes from a list of well-known people/companies (Google and Amazon spokespeople, Forrester analyst, Nick Carr). But these quotes all address the generic idea of utility computing standards, not the specifics of Bert’s project.
- Saying that “several small cloud-computing firms including Elastra and Rightscale are already on board with 3Tera’s standards group” is ambiguous. Are they on-board with specific goals and a candidate specification? Or are they on board with the general idea that it might be time to talk about some kind of standard in the general area of utility computing?
- IEEE and W3C are listed as possible hosts for the effort, but they don’t seem like a very good match for this area. I would have thought of DMTF, OASIS or even OGF first. On the face of it, DMTF might be the best place but I fear that companies like 3Tera, Rightscale and Elastra would be eaten alive by the board member companies there. It would be almost impossible for them to drive their vision to completion, unlike what they can do in an OASIS working group.
- A new consortium might be an option, but a risky and expensive one. I have sometimes wondered (after seeing sad episodes of well-meaning and capable start-ups being ripped apart by entrenched large vendors in standards groups) why VCs don’t play a more active role in standards. Standards sound like the kind of thing VCs should be helping their companies with. VC firms are pretty used to working together, jointly investing in companies. Creating a new standard consortium might be too hard for 3Tera, but if the VCs behind 3Tera, Elastra and Rightscale got together and looked at the utility computing companies in their portfolios, it might make sense to join forces on some well-scoped standardization effort that may not otherwise be given a chance in existing groups.
- I hope Bert will look into the history of DCML, a similar effort (it was about data center automation, which utility computing is not that far from once you peel away the glossy pictures) spearheaded by a few best-of-bread companies but ignored by the big boys. It didn’t really take off. If it had, utility computing standards might now be built as an update/extension of that specification. Of course DCML started as a new consortium and ended as an OASIS “member section” (a glorified working group), so this puts a grain of salt on my “create a new consortium and/or OASIS group” suggestion above.
- The effort can’t afford to be disconnected from other standards in the virtualization and IT management domains. How does the effort relate to OVF? To WS-Management? To existing modeling frameworks? That’s the main draw towards DMTF as a host.
- What’s the open source side of this effort? As John mentions during the latest Redmonk/Willis IT management podcast (starting around minute 24), there needs to a open source side to this. Actually, John thinks all you need is the open source side. Coté brings up Eucalyptus. BTW, if you want an existing combination of standards and open source, have a look at CDDLM (standard) and SmartFrog (implementation, now with EC2/S3 deployment)
- There seems to be some solid technical raw material to start from. 3Tera’s ADL, combined with Elastra’s ECML/EDML, presumably captures a fair amount of field expertise already. But when you think of them as a starting point to standardization, the mindset needs to switch from “what does my product need to work” to “what will the market adopt that also helps my product to work”.
- One big question (at least from my perspective) is that of the line between infrastructure and applications. Call me biased, but I think this effort should focus on the infrastructure layer. And provide hooks to allow application-level automation to drive it.
- The other question is with regards to the management aspect of the resulting system and the role management plays in whatever standard specification comes out of Bert’s effort.
Bottom line: I applaud Bert’s efforts but I couldn’t sleep well tonight if I didn’t also warn him that “there be dragons”.
And for those who haven’t seen it yet, here is a very good document on the topic (but it is focused on big vendors, not on how smaller companies can play the standards game).
[UPDATED 2008/6/30: A couple hours after posting this, I see that Coté has just published a blog post that elaborates on his view of cloud standards. As an addition to the podcast I mentioned earlier.]
[UPDATED 2008/7/2: If you read this in your feed viewer (rather than directly on vambenepe.com) and you don’t see the comments, you should go have a look. There are many clarifications and some additional insight from the best authorities on the topic. Thanks a lot to all the commenters.]
Filed under Amazon, Automation, Business, DMTF, Everything, Google, Google App Engine, Grid, HP, IBM, IT Systems Mgmt, Mgmt integration, Modeling, OVF, Portability, Specs, Standards, Utility computing, Virtualization
BMC acquires ITM Software
Another BMC acquisition today: ITM Software. Their software suite is designed to help drive IT decisions from the point of view of their business impact.
This is important, of course, for all the reasons that BMC, HP, Oracle and others have been explaining for a while (how often have you heard the word “alignment” over the last three years, compared to the previous thirty?). It’s becoming even more important now, as the options for IT sourcing (from the traditional “give it all to Unisys”, to SaaS, to running your own apps in a utility computing environment…) are multiplicating. Choosing between Intel and AMD CPUs in your datacenter is a technical decision, but choosing between an on-premise application, a SaaS application and running your application on EC2 is driven by business considerations of cost, risks, control, flexibility, etc. And it’s not just a one-time decision, it’s the day to day management that follows these decisions.
I don’t know much about the current ITM offering, but it was never clear to me how much they could deliver as a narrow layer, separate from the heavy-duty IT management stack (I can see how they would deliver financial and project management tools, but what about *really* linking day to day IT administration decisions to the business impact). Being part of BMC, presumably allowing deeper integration into real IT management operations, seems to make sense.
I just wish they didn’t make it sound so easy: “BMC’s purchase of ITM Software creates a unique, integrated solution that provides customers with a single comprehensive view into…”. So just signing the check creates the integration? Now I am going to get calls from our execs asking why it takes so much work to integrate acquired products, if BMC can do it the same day they sign the deal…
While I am at it, here is the press release that HP put out to list the announcements at their Software Universe conference this week. I notice that it’s all about new versions of ex-Mercury products. No OpenView, Peregrine or Opsware content, as far as I can tell. Without looking at it in more details I don’t know how different these new versions really are. What appears pretty new is the SaaS offering (also based on Mercury products) at the end of the press release. On the nitpicking side, can anyone tell me what these “static configuration management databases” are that are “unable to support the real-time needs of today’s complex technology environments”? I can see how a “static” database would be hard-pressed to help, but I haven’t noticed any vendor selling read-only config stores.
[UPDATED 2008/6/18: More details about the HP announcement at InfoWorld. Including quotes from my ex-boss Ramin. Congrats on getting UCMDB 7.5 out of the door!]
Filed under Application Mgmt, BSM, Business, CMDB, Everything, HP, IT Systems Mgmt, ITIL, Mgmt integration