Category Archives: Governance
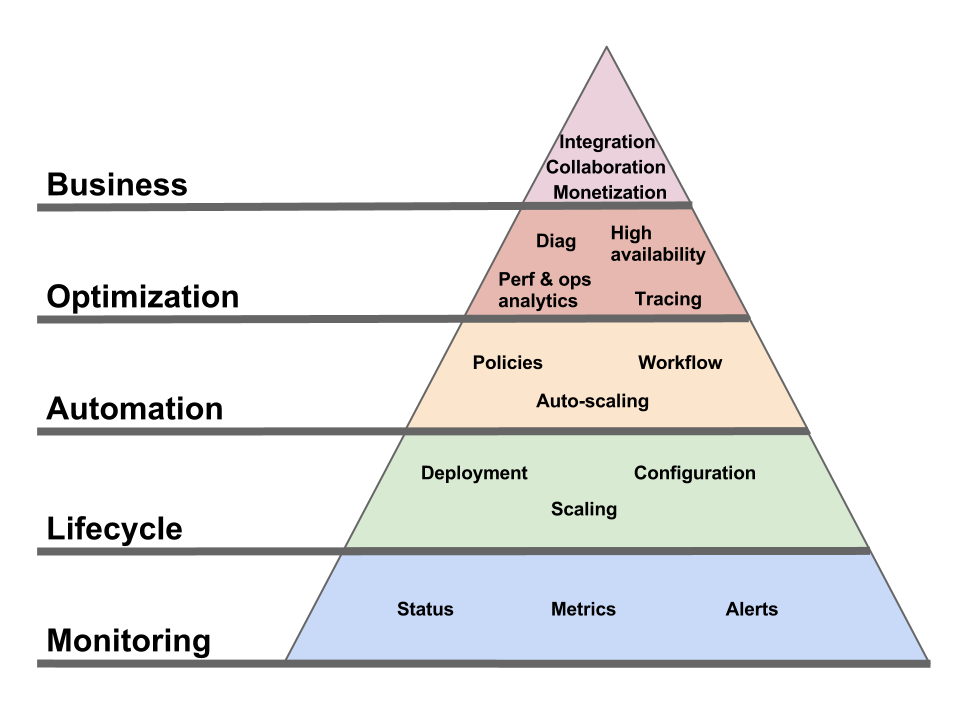
Pyramid of needs for Cloud management
Comments Off on Pyramid of needs for Cloud management
Filed under Application Mgmt, Automation, Business, Cloud Computing, Everything, Governance, IT Systems Mgmt, Manageability, Utility computing
Perspectives on Cloud.com acquisition
Interesting analysis (by Gartner’s Lydia Leong) on the acquisition of Cloud.com by Citrix (apparently for 100x revenues) and its position as a cheaper alternative for vCloud (at least until OpenStack Nova becomes stable).
Great read, even though that part:
“[Zygna] uses Cloud.com to provide Amazon-compatible (and thus Rightscale-compatible) infrastructure internally, letting it easily move workloads across their own infrastructure and Amazon’s.”
While I’m at it, here’s another take on Cloud.com, this time from an OSS license perspective. Namely, the difference between building your business on GPL (like Eucalyptus) or Apache 2 (like the more community-driven open source projects such as OpenStack).
Towards the end, there’s also a nice nod to the Oracle Cloud API:
“DMTF has been receiving other submissions for an API standard. Oracle has made its submission public. It is based on an earlier Sun proposal, and it is the best API we have yet seen. Furthermore, Oracle has identified a core subset to allow initial early adoption, as well as areas where vendors (including themselves and crucially VMware) may continue to extend to allow differentiation.”
Here’s more on the Oracle Cloud API, including an explanation of the “core/extension” split mentioned above.
Comments Off on Perspectives on Cloud.com acquisition
Filed under Cloud Computing, DMTF, Everything, Governance, Mgmt integration, Open source, OpenStack, Oracle, Specs, Standards, Utility computing, Virtualization, VMware
Reading IBM’s proposed standard for Cloud Architecture
Did you enjoy the first version of IBM’s Cloud Computing Reference Architecture? Did you even get certified on it? Then rejoice, because there’s a new version. IBM recently submitted the IBM Cloud Computing Reference Architecture 2.0 to The Open Group.
I’m a bit out of practice reading this kind of IBMese (let’s just say that The Open Group was the right place to submit it) but I would never let my readers down. So, even though these box-within-a-box-within-a-box diagrams (see section 2) give me flashbacks to the days of OGF and WSRF, I soldiered on.
I didn’t understand the goal of the document enough to give you a fair summary, but I can share some thoughts.
It starts by talking a lot about SOA. I initially thought this was to make the point that Glen Daniels articulated very well in this tweet:
Yup, correct SOA patterns (loose coupling, dyn refs, coarse interfaces…) are exactly what you need for cloud apps. You knew this.
But no. Rather than Glen’s astute remark, IBM’s point is one meta-level lower. It’s that “Cloud solutions are SOA solutions”. Which I have a harder time parsing. If you though “service” was overloaded before…
While some of the IBM authors are SOA experts, others apparently come from a Telco background so we get OSS/BSS analogies next.
By that point, I’ve learned that Cloud is like SOA except when it’s like Telco (but there’s probably another reference architecture somewhere that explains that Telco is SOA, so it all adds up).
One thing that chagrined me was that even though this document is very high-level it still manages to go down into implementatin technologies long enough to assert, wrongly, that virtualization is required for Cloud solutions. Another Cloud canard repeated here is the IaaS/PaaS/SaaS segmentation of the Cloud world, to which IBM adds a BPaaS (Business Process as a Service) layer for good measure (for my take on how Cloud relates to SOA, and how I dislike the IaaS/PaaS/SaaS pyramid, see this write-up of the presentation I gave at last year’s Cloud Connect, especially the 3rd picture).
It gets a lot better if you persevere to page 29, where the “Architecture Principles” finally get introduced (if had been asked to edit the paper, I would have only kept the last 6 pages). They are:
- Design for Cloud-scale Efficiencies: When realizing cloud characteristics such as elasticity, self-service access, and flexible sourcing, the cloud design is strictly oriented to high cloud scale efficiencies and short time-to-delivery/time-to-change. (“Efficiency Principle”)
- Support Lean Service Management: The Common Cloud Management Platform fosters lean and lightweight service management policies, processes, and technologies. (“Lightweightness Principle”)
- Identify and Leverage Commonalities: All commonalities are identified and leveraged in cloud service design. (“Economies-of-scale principle”)
- Define and Manage generically along the Lifecycle of Cloud Services: Be generic across I/P/S/BPaaS & provide ‘exploitation’ mechanism to support various cloud services using a shared, common management platform (“Genericity”).
Each principle gets a nickname, thanks to which IBM can refer to this list as the ELEG principles (Efficiency, Lightweightness, Economies-of-scale, Genericity). It also spells GLEE, but apparently that’s wasn’t the prefered sequence.
The first principle is hard to disagree with. The second also rings true, including its dings on ITIL (but the irony of IBM exhaulting “Lightweightness” is hard to ignore). The third and fourth principles (by that time I had lost too many brain cells to understand how they differ) really scared me. While I can understand the motivation, they elicited a vision of zombies in blue suits (presumably undead IBM Distinguish Engineers and Fellows) staggering towards me: “frameworks… we want frameworks…”.
There you go. If you want more information (and, more importantly, unbiased information) go read the Reference Architecture yourself. I am not involved in The Open Group, and I have no idea what it plans to do with it (and if it has received other submissions of the same type). Though I wouldn’t be surprised if I see, in 5 years, some panic sales rep asking an internal mailing list “The customer RPF asks for a mapping of our solution to the Open Group Cloud Reference Architecture and apparently IBM has 94 slides about it, what do I do? Has anyone heard about this Reference Architecture? This is urgent.”
Urgent things are long in the making.
Redeeming the service description document
A bicycle is a convenient way to go buy cigarettes. Until one day you realize that buying cigarettes is a bad idea. At which point you throw away your bicycle.
Sounds illogical? Well, that’s pretty much what the industry has done with service descriptions. It went this way: people used WSDL (and stub generation tools built around it) to build distributed applications that shared too much. Some people eventually realized that was a bad approach. So they threw out the whole idea of a service description. And now, in the age of APIs, we are no more advanced than we were 15 years ago in terms of documenting application contracts. It’s tragic.
The main fallacies involved in this stagnation are:
- Assuming that service descriptions are meant to auto-generate all-encompassing program stubs,
- Looking for the One True Description for a given service,
- Automatically validating messages based on the service description.
I’ll leave the first one aside, it’s been widely covered. Let’s drill in a bit into the other two.
There is NOT One True Description for a given service
Many years ago, in the same galaxy where we live today (only a few miles from here, actually), was a development team which had to implement a web service for a specific WSDL. They fed the WSDL to their SOAP stack. This was back in the days when WSDL interoperability was a “promise” in the “political campaign” sense of the term so of course it didn’t work. As a result, they gave up on their SOAP stack and implemented the service as a servlet. Which, for a team new to XML, meant a long delay and countless bugs. I’ll always remember the look on the dev lead’s face when I showed him how 2 minutes and a text editor were all you needed to turn the offending WSDL in to a completely equivalent WSDL (from the point of view of on-the-wire messages) that their toolkit would accept.
(I forgot what the exact issue was, maybe having operations with different exchange patterns within the same PortType; or maybe it used an XSD construct not supported by the toolkit, and it was just a matter of removing this constraint and moving it from schema to code. In any case something that could easily be changed by editing the WSDL and the consumer of the service wouldn’t need to know anything about it.)
A service description is not the literal word of God. That’s true no matter where you get it from (unless it’s hand-delivered by an angel, I guess). Just because adding “?wsdl” to the URL of a Web service returns an XML document doesn’t mean it’s The One True Description for that service. It’s just the most convenient one to generate for the app server on which the service is deployed.
One of the things that most hurts XML as an on-the-wire format is XSD. But not in the sense that “XSD is bad”. Sure, it has plenty of warts, but what really hurts XML is not XSD per se as much as the all-too-common assumption that if you use XML you need to have an XSD for it (see fat-bottomed specs, the key message of which I believe is still true even though SML and SML-IF are now dead).
I’ve had several conversations like this one:
– The best part about using JSON and REST was that we didn’t have to deal with XSD.
– So what do you use as your service contract?
– Nothing. Just a human-readable wiki page.
– If you don’t need a service contract, why did you feel like you had to write an XSD when you were doing XML? Why not have a similar wiki page describing the XML format?
– …
It’s perfectly fine to have service descriptions that are optimized to meet a specific need rather than automatically focusing on syntax validation. Not all consumers of a service contract need to be using the same description. It’s ok to have different service descriptions for different users and/or purposes. Which takes us to the next fallacy. What are service descriptions for if not syntax validation?
A service description does NOT mean you have to validate messages
As helpful as “validation” may seem as a concept, it often boils down to rejecting messages that could otherwise be successfully processed. Which doesn’t sound quite as useful, does it?
There are many other ways in which service descriptions could be useful, but they have been largely neglected because of the focus on syntactic validation and stub generation. Leaving aside development use cases and looking at my area of focus (application management), here are a few use cases for service descriptions:
Creating test messages (aka “synthetic transactions”)
A common practice in application management is to send test messages at regular intervals (often from various locations, e.g. branch offices) to measure the availability and response time of an application from the consumer’s perspective. If a WSDL is available for the service, we use this to generate the skeleton of the test message, and let the admin fill in appropriate values. Rather than a WSDL we’d much rather have a “ready-to-use” (possibly after admin review) test message that would be provided as part of the service description. Especially as it would be defined by the application creator, who presumably knows a lot more about that makes a safe and yet relevant message to send to the application as a ping.
Attaching policies and SLAs
One of the things that WSDLs are often used for, beyond syntax validation and stub generation, is to attach policies and SLAs. For that purpose, you really don’t need the XSD message definition that makes up so much of the WSDL. You really just need a way to identify operations on which to attach policies and SLAs. We could use a much simpler description language than WSDL for this. But if you throw away the very notion of a description language, you’ve thrown away the baby (a classification of the requests processed by the service) along with the bathwater (a syntax validation mechanism).
Governance / versioning
One benefit of having a service description document is that you can see when it changes. Even if you reduce this to a simple binary value (did it change since I last checked, y/n) there’s value in this. Even better if you can introspect the description document to see which requests are affected by the change. And whether the change is backward-compatible. Offering the “before” XSD and the “after” XSD is almost useless for automatic processing. It’s unlikely that some automated XSD inspection can tell me whether I can keep using my previous messages or I need to update them. A simple machine-readable declaration of that fact would be a lot more useful.
I just listed three, but there are other application management use cases, like governance/auditing, that need a service description.
In the SOAP world, we usually make do with WSDL for these tasks, not because it’s the best tool (all we really need is a way to classify requests in “buckets” – call them “operations” if you want – based on the content of the message) but because WSDL is the only understanding that is shared between the caller and the application.
By now some of you may have already drafted in your head the comment you are going to post explaining why this is not a problem if people just use REST. And it’s true that with REST there is a default categorization of incoming messages. A simple matrix with the various verbs as columns (GET, POST…) and the various resource types as rows. Each message can be unambiguously placed in one cell of this matrix, so I don’t need a service description document to have a request classification on which I can attach SLAs and policies. Granted, but keep these three things in mind:
- This default categorization by verb and resource type can be a quite granular. Typically you wouldn’t have that many different policies on your application. So someone who understands the application still needs to group the invocations into message categories at the right level of granularity.
- This matrix is only meaningful for the subset of “RESTful” apps that are truly… RESTful. Not for all the apps that use REST where it’s an easy mental mapping but then define resource types called “operations” or “actions” that are just a REST veneer over RPC.
- Even if using REST was a silver bullet that eliminated the need for service definitions, as an application management vendor I don’t get to pick the applications I manage. I have to have a solution for what customers actually do. If I restricted myself to only managing RESTful applications, I’d shrink my addressable market by a few orders of magnitude. I don’t have an MBA, but it sounds like a bad idea.
This is not a SOAP versus REST post. This is not a XML versus JSON post. This is not a WSDL versus WADL post. This is just a post lamenting the fact that the industry seems to have either boxed service definitions into a very limited use case, or given up on them altogether. It I wasn’t recovering from standards burnout, I’d look into a versatile mechanism for describing application services in a way that is geared towards message classification more than validation.
Comments Off on Redeeming the service description document
Filed under API, Application Mgmt, Everything, Governance, IT Systems Mgmt, Manageability, Mashup, Mgmt integration, Middleware, Modeling, Protocols, REST, SML, SOA, Specs, Standards
The Tragedy of the Commons in Cloud standards
I wasn’t at the OSCON Cloud Summit this past week, but I’ve spent some time over the weekend trying to collect the good bits. Via Twitter, I had heard echos of an interesting debate on Cloud standards between Sam Johnston and Benjamin Black. Today I got to see Benjamin’s slides and read reports from two audience members, Charles Engelke and Krishnan Subramanian. Sam argued that Cloud standards are needed, Benjamin that they would be premature.
Benjamin is right about what to think and Sam is right about what to do.
Let me put it differently: Benjamin is right in theory, but it doesn’t matter. Here is why.
Say I’m a vendor and Benjamin convinces me
Assume I truly believe the industry would be better served if we all waited. Does this mean I’ll stay away from Cloud standards efforts for now? Not necessarily, because nothing is stopping my competitors from doing it. In the IT standards world, your only choice is to participate or opt out. For the most part you can’t put your muscle towards stopping an effort. Case in point, Amazon has so far chosen to opt out; has that stopped VMWare and others from going to DMTF and elsewhere to ratify specifications as standards? Of course not. To the contrary, it has made the option even more attractive because when the leader stays home it is a lot easier for less popular candidates to win the prize. So as a vendor-who-was-convinced-by-Benjamin I now have the choice between letting my competitor get his specification rubberstamped (and then hit me with the competitive advantage of being “standard compliant” and even “the standard leader”) or getting involved in an effort that I know to be counterproductive for the industry. Guess what most will choose?
Even the initial sinner (who sets the wheels of premature standardization in motion) may himself be convinced that it’s too early for Cloud standards. But he has to assume that one of his competitors will make the move, and in that context why give them first mover advantage (and the choice of the battlefield). It’s the typical Tragedy of the Commons scenario. By acting in a rational and self-interested way, participants invariably end up creating a bad situation, one that they might all know is against everyone’s self interest.
And it’s not just vendors.
Say I’m an officer of a Standard-setting organization and Benjamin convinces me
If you expect that I would use my position in the organization to prevent companies from starting a Cloud standard effort there, you live in fantasy-land. Standard-setting organizations compete with one another just as fiercely as companies do. If I have achieved a position of leadership in a given standard organization, the last thing I want is to see another organization lay claims to a strategic and fast-growing area of the IT landscape. It takes a lot of time and money for a company to get elected on the right board and gets its employees (or other reliable allies) in the right leadership positions. Or to acquire people already in that place. You only get a return on that investment if the organization manages to be the one where the key standards get created. That’s what’s behind the landgrab reflex of many standards organizations.
And it goes beyond vendors and standards organizations
Say I’m an IT buyer and Benjamin convinces me
Assume I really believe Cloud standards are premature. Assume they get created anyway and I have to choose between a vendor who supports them and one who doesn’t. Do I, as a matter of principle, refuse consider the “standard-compliant” label in my purchasing decision? Even if I know that the standard shouldn’t have been created, I also know that, all other things being equal, the “standard-compliant” product will attract more tools and complementary solutions and will likely ease future integration problems.
And then there is the question of how I’ll explain this to my boss. Will Benjamin be by my side with his beautiful slides when I am called in an emergency meeting to explain to the CIO why we, unlike the competitors, didn’t pick “a standards-based solution”?
In the real world, the only way to solve problems caused by the Tragedy of the Commons is to have some overarching authority regulate the usage of the resource at risk of being ruined. This seems unlikely to be a workable solution when the resource is not a river to protect from sewer discharges but an IT domain to protect from premature standardization. If called, I’d be happy to serve as benevolent dictator for the IT industry (I could fix a few other things beyond the Cloud standards landgrab issue). But as long as neither I nor anyone else is in a dictatorial position, Benjamin’s excellent exposé has no audience for which his call to arms (or rather to lay down the arms) is actionable. I am not saying that everyone agrees with Benjamin, but that even if everyone did it still wouldn’t make a difference. Many of us in the industry share his views and rationally act as if we didn’t.
[UPDATED 2010/7/25: In a nice example of Blog/Twitter synergy, minutes after posting this I was having a conversation on Twitter with Benjamin Black about my interpretation of what he said. Based on this conversation, I realize that I should clarify that what I mean by “standards” in this post is “something that comes out of a standard-setting organization” (whether or not it gets adopted), in other words what Benjamin calls a “standard specification”. He uses the word “standard” to mean “what most people use”, which may or may not be a “standard specification”. That’s a big part of the disconnect that led to our Twitter chat. The other part is that what I presented as Benjamin’s thesis in my post is actually only one of the propositions in his talk, and not even the main one. It’s the proposition that it is damaging for the industry when a standard specification comes out of a standard organization too early. I wasn’t at the conference where Benjamin presented but it’s hard to understand anything else out of slide 61 (“standardize too soon, and you lock to the wrong thing”) and 87 (“to discover the right standards, we must eschew standards”). So if I misrepresented him I believe it was in making it look like this was the focus of his talk while in fact it was only one of the points he made. As he himself clarified for me: “My _actual_ argument is that it doesn’t matter what we think about cloud standards, if they are needed, they will emerge” (again, in this sentence he uses “standards” to mean “something that people have converged on”).
More generally, my main point here has nothing to do with Benjamin, Sam and their OSCON debate, other than the fact that reading about it prompted me to type this blog entry. It’s simply that there is a perversion in the IT standards landscape that makes it impossible for premature standardization *not* to happen. It’s something I’ve written before, e.g. in this post:
Saying “it’s too early” in the standards world is the same as saying nothing. It puts you out of the game and has no other effect. Amazon, the clear leader in the space, has taken just this position. How has this been understood? Simply as “well I guess we’ll do it without them”. It’s sad, but all it takes is one significant (but not necessarily leader) company trying to capitalize on some market influence to force the standards train to leave the station. And it’s a hard decision for others to not engage the pursuit at that point. In the same way that it only takes one bellicose country among pacifists to start a war.
Benjamin is just a messenger; and I wasn’t trying to shoot him.]
[UPDATED 2010/8/13: The video of the debate between Sam Johnston and Benjamin Black is now available, so you can see for yourself.]
Filed under Amazon, Big picture, Cloud Computing, DMTF, Ecology, Everything, Governance, Standards, Utility computing, VMware
“Freeing SaaS from Cloud”: slides and notes from Cloud Connect keynote
I got invited to give a short keynote presentation during the Cloud Connect conference this week at the Santa Clara Convention Center (thanks Shlomo and Alistair). Here are the slides (as PPT and PDF). They are visual support for my bad jokes rather than a medium for the actual message. So here is an annotated version.

I used this first slide (a compilation of representations of the 3-layer Cloud stack) to poke some fun at this ubiquitous model of the Cloud architecture. Like all models, it’s neither true nor false. It’s just more or less useful to tackle a given task. While this 3-layer stack can be relevant in the context of discussing economic aspects of Cloud Computing (e.g. Opex vs. Capex in an on-demand world), it is useless and even misleading in the context of some more actionable topics for SaaS: chiefly, how you deliver such services, how you consume them and how you manage them.
In those contexts, you shouldn’t let yourself get too distracted by the “aaS” aspect of SaaS and focus on what it really is.

Which is… a web application (by which I include both HTML access for humans and programmatic access via APIs.). To illustrate this point, I summarized the content of this blog entry. No need to repeat it here. The bottom line is that any distinction between SaaS and POWA (Plain Old Web Applications) is at worst arbitrary and at best concerned with the business relationship between the provider and the consumer rather than technical aspects of the application.
Which means that for most technical aspect of how SaaS is delivered, consumed and managed, what you should care about is that you are dealing with a Web application, not a Cloud service. To illustrate this, I put up the…

… guillotine slide. Which is probably the only thing people will remember from the presentation, based on the ample feedback I got about it. It probably didn’t hurt that I also made fun of my country of origin (you can never go wrong making fun of France), saying that the guillotine was our preferred way of solving any problem and also the last reliable piece of technology invented in France (no customer has ever come back to complain). Plus, enough people in the audience seemed to share my lassitude with the 3-layer Cloud stack to find its beheading cathartic.
Come to think about it, there are more similarities. The guillotine is to the axe what Cloud Computing is to traditional IT. So I may use it again in Cloud presentations.
Of course this beheading is a bit excessive. There are some aspects for which the IaaS/PaaS/SaaS continuum makes sense, e.g. around security and compliance. In areas related to multi-tenancy and the delegation of control to a third party, etc. To the extent that these concerns can be addressed consistently across the Cloud stack they should be.
But focusing on these “Cloud” aspects of SaaS is missing the forest for the tree.
A large part of the Cloud value proposition is increased flexibility. At the infrastructure level, being able to provision a server in minutes rather than days or weeks, being able to turn one off and instantly stop paying for it, are huge gains in flexibility. It doesn’t work quite that way at the application level. You rarely have 500 new employees joining overnight who need to have their email and CRM accounts provisioned. This is not to minimize the difficulties of deploying and scaling individual applications (any improvement is welcome on this). But those difficulties are not what is crippling the ability of IT to respond to business needs.
Rather, at the application level, the true measure of flexibility is the control you maintain on your business processes and their orchestration across applications. How empowered (or scared) you are to change them (either because you want to, e.g. entering a new business, or because you have to, e.g. a new law). How well your enterprise architecture has been defined and implemented. How much visibility you have into the transactions going through your business applications.
It’s about dealing with composite applications, whether or not its components are on-premise or “in the Cloud”. Even applications like Salesforce.com see a large number of invocations from their APIs rather than their HTML front-end. Which means that there are some business applications calling them (either other SaaS, custom applications or packaged applications with an integration to Salesforce). Which means that the actual business transactions go across a composite system and have to be managed as such, independently of the deployment model of each participating application.
[Side note: One joke that fell completely flat was that it was unlikely that the invocations of Salesforce through the Web services APIs be the works of sales people telneting to port 80 and typing HTTP and SOAP headers. Maybe I spoke too quickly (as I often do), or the audience was less nerdy than I expected (though I recognized some high-ranking members of the nerd aristocracy). Or maybe they all got it but didn’t laugh because I forgot to take encryption into account?]
At this point I launched into a very short summary of the benefits of SOA governance/management, real user experience monitoring, BTM and application-centric IT management in general. Which is very succinctly summarized on the slide by the “SOA” label on the receiving bucket. I would have needed another 10 minutes to do this subject justice. Maybe at Cloud Connect 2011? Alistair?

This picture of me giving the presentation at Cloud Connect is the work of Alex Dunne.
The guillotine picture is the work of Rusty Boxcars who didn’t just take the photo but apparently built the model (yes it’s a small-size model, look closely). Here it is in its original, unedited, glory. My edited version is available under the same CC license to anyone who wants to grab it.
Oracle acquires Amberpoint
Oracle just announced that it has purchased Amberpoint. If you have ever been interested in Web services management, then you surely know about Amberpoint. The company has long led the pack of best-of-breed vendors for Web services and SOA Management. My history with them goes back to the old days of the OASIS WSDM technical committee, where their engineers brought to the group a unique level of experience and practical-mindedness.
The official page has more details. In short, Amberpoint is going to reinforce Oracle Enterprise Manager, especially in these areas:
- Business Transaction Management
- SOA Management
- Application Performance Management
- SOA Governance (BTW, Oracle Enterprise Repository 11g was released just over a week ago)
I am looking forward to working with my new colleagues from Amberpoint.
Generalizing the Cloud vs. SOA Governance debate
There have been some interesting discussions recently about the relationship between Cloud management and SOA management/governance (run-time and design-time). My only regret is that they are a bit too focused on determining winners and loosers rather than defining what victory looks like (a bit like arguing whether the smartphone is the triumph of the phone over the computer or of the computer over the phone instead of discussing what makes a good smartphone).
To define victory, we need to answer this seemingly simple question: in what ways is the relationship between a VM and its hypervisor different from the relationship between two communicating applications?
More generally, there are three broad categories of relationships between the “active” elements of an IT system (by “active” I am excluding configuration, organization, management and security artifacts, like patch, department, ticket and user, respectively, to concentrate instead on the elements that are on the invocation path at runtime). We need to understand if/how/why these categories differ in how we manage them:
- Deployment relationships: a machine (or VM) in a physical host (or hypervisor), a JEE application in an application server, a business process in a process engine, etc…
- Infrastructure dependency relationships (other than containment): from an application to the DB that persists its data, from an application tier to web server that fronts it, from a batch job to the scheduler that launches it, etc…
- Application dependency relationships: from an application to a web service it invokes, from a mash-up to an Atom feed it pulls, from a portal to a remote portlet, etc…
In the old days, the lines between these categories seemed pretty clear and we rarely even thought of them in the same terms. They were created and managed in different ways, by different people, at different times. Some were established as part of a process, others in a more ad-hoc way. Some took place by walking around with a CD, others via a console, others via a centralized repository. Some of these relationships were inventoried in spreadsheets, others on white boards, some in CMDBs, others just in code and in someone’s head. Some involved senior IT staff, others were up to developers and others were left to whoever was manning the controls when stuff broke.
It was a bit like the relationships you have with the taxi that takes you to the airport, the TSA agent who scans you and the pilot who flies you to your destination. You know they are all involved in your travel, but they are very distinct in how you experience and approach them.
It all changes with the Cloud (used as a short hand for virtualization, management automation, on-demand provisioning, 3rd-party hosting, metered usage, etc…). The advent of the hypervisor is the most obvious source of change: relationships that were mostly static become dynamic; also, where you used to manage just the parts (the host and the OS, often even mixed as one), you now manage not just the parts but the relationship between them (the deployment of a VM in a hypervisor). But it’s not just hypervisors. It’s frameworks, APIs, models, protocols, tools. Put them all together and you realize that:
- the IT resources involved in all three categories of relationships can all be thought of as services being consumed (an “X86+ethernet emulation” service exposed by the hypervisor, a “JEE-compatible platform” service exposed by the application server, an “RDB service” expose by the database, a Web services exposed via SOAP or XML/JSON over HTTP, etc…),
- they can also be set up as services, by simply sending a request to the API of the service provider,
- not only can they be set up as services, they are also invoked as such, via well-documented (and often standard) interfaces,
- they can also all be managed in a similar service-centric way, via performance metrics, SLAs, policies, etc,
- your orchestration code may have to deal with all three categories, (e.g. an application slowdown might be addressed either by modifying its application dependencies, reconfiguring its infrastructure or initiating a new deployment),
- the relationships in all these categories now have the potential to cross organization boundaries and involve external providers, possibly with usage-based billing,
- as a result of all this, your IT automation system really needs a simple, consistent, standard way to handle all these relationships. Automation works best when you’ve simplified and standardize the environment to which it is applied.
If you’re a SOA person, your mental model for this is SOA++ and you pull out your SOA management and governance (config and runtime) tools. If you are in the WS-* obedience of SOA, you go back to WS-Management, try to see what it would take to slap a WSDL on a hypervisor and start dreaming of OVF over MTOM/XOP. If you’re into middleware modeling you might start to have visions of SCA models that extend all the way down to the hardware, or at least of getting SCA and OSGi to ally and conquer the world. If you’re a CMDB person, you may tell yourself that now is the time for the CMDB to do what you’ve been pretending it was doing all along and actually extend all the way into the application. Then you may have that “single source of truth” on which the automation code can reliably work. Or if you see the world through the “Cloud API” goggles, then this “consistent and standard” way to manage relationships at all three layers looks like what your Cloud API of choice will eventually do, as it grows from IaaS to PaaS and SaaS.
Your background may shape your reference model for this unified service-centric approach to IT management, but the bottom line is that we’d all like a nice, clear conceptual model to bridge and unify Cloud (provisioning and containment), application configuration and SOA relationships. A model in which we have services/containers with well-defined operational contracts (and on-demand provisioning interfaces). Consumers/components with well-defined requirements. APIs to connect the two, with predictable results (both in functional and non-functional terms). Policies and SLAs to fine-tune the quality of service. A management framework that monitors these policies and SLAs. A common security infrastructure that gets out of the way. A metering/billing framework that spans all these interactions. All this while keeping out of sight all the resource-specific work needed behind the scene, so that the automation code can look as Zen as a Japanese garden.
It doesn’t mean that there won’t be separations, roles, processes. We may still want to partition the IT management tasks, but we should first have a chance to rejigger what’s in each category. It might, for example, make sense to handle provider relationships in a consistent way whether they are “deployment relationships” (e.g. EC2 or your private IaaS Cloud) or “application dependency relationships” (e.g. SOA, internal or external). On the other hand, some of the relationships currently lumped in the “infrastructure dependency relationships” category because they are “config files stuff” may find different homes depending on whether they remain low-level and resource-specific or they are absorbed in a higher-level platform contract. Any fracture in the management of this overall IT infrastructure should be voluntary, based on legal, financial or human requirements. And not based on protocol, model, security and tool disconnect, on legacy approaches, on myopic metering, that we later rationalize as “the way we’d want things to be anyway because that’s what we are used to”.
In the application configuration management universe, there is a planetary collision scheduled between the hypervisor-centric view of the world (where virtual disk formats wrap themselves in OVF, then something like OVA to address, at least at launch time, application and infrastructure dependency relationships) and the application-model view of the world (SOA, SCA, Microsoft Oslo at least as it was initially defined, various application frameworks…). Microsoft Azure will have an answer, VMWare/Springsouce will have one, Oracle will too (though I can’t talk about it), Amazon might (especially as it keeps adding to its PaaS portfolio) or it might let its ecosystem sort it out, IBM probably has Rational, WebSphere and Tivoli distinguished engineers locked into a room, discussing and over-engineering it at this very minute, etc.
There is a lot at stake, and it would be nice if this was driven (industry-wide or at least within each of the contenders) by a clear understanding of what we are aiming for rather than a race to cobble together partial solutions based on existing control points and products (e.g. the hypervisor-centric party).
[UPDATED 2010/1/25: For an illustration of my statement that “if you’re a SOA person, your mental model for this is SOA++”, see Joe McKendrick’s “SOA’s Seven Greatest Mysteries Unveiled” (bullet #6: “When you get right down to it, cloud is the acquisition or provisioning of reusable services that cross enterprise walls. (…) They are service oriented architecture, and they rely on SOA-based principles to function.”)]
Cloud platform patching conundrum: PaaS has it much worse than IaaS and SaaS
The potential user impact of changes (e.g. patches or config changes) made on the Cloud infrastructure (by the Cloud provider) is a sore point in the Cloud value proposition (see Hoff’s take for example). You have no control over patching/config actions taken by the provider, any of which could potentially affect you. In a traditional data center, you can test the various changes on specific applications; you don’t have to apply them at the same time on all servers; and you can even decide to skip some infrastructure patches not relevant to your application (“if it aint’ broken…”). Not so in a Cloud environment, where you may not even know about a change until after the fact. And you have no control over the timing and the roll-out of the patch, so that some of your instances may be running on patched nodes and others may not (good luck with troubleshooting that).
Unfortunately, this is even worse for PaaS than IaaS. Simply because you seat on a lot more infrastructure that is opaque to you. In a IaaS environment, the only thing that can change is the hardware (rarely a cause of problem) and the hypervisor (or equivalent Cloud OS). In a PaaS environment, it’s all that plus whatever flavor of OS and application container is used. Depending on how streamlined this all is (just enough OS/AS versus a traditional deployment), that’s potentially a lot of code and configuration. Troubleshooting is also somewhat easier in a IaaS setup because the error logs are localized (or localizable) to a specific instance. Not necessarily so with PaaS (and even if you could localize the error, you couldn’t guarantee that your troubleshooting test runs on the same node anyway).
In a way, PaaS is squeezed between IaaS and SaaS on this. IaaS gets away with a manageable problem because the opaque infrastructure is not too thick. For SaaS it’s manageable too because the consumer is typically either a human (who is a lot more resilient to change) or a very simple and well-understood interface (e.g. IMAP or some Web services). Contrast this with PaaS where the contract is that of an application container (e.g. JEE, RoR, Django).There are all kinds of subtle behaviors (e.g, timing/ordering issues) that are not part of the contract and can surface after a patch: for example, a bug in the application that was never found because before the patch things always happened in a certain order that the application implicitly – and erroneously – relied on. That’s exactly why you always test your key applications today even if the OS/AS patch should, in theory, not change anything for the application. And it’s not just patches that can do that. For example, network upgrades can introduce timing changes that surface new issues in the application.
And it goes both ways. Just like you can be hurt by the Cloud provider patching things, you can be hurt by them not patching things. What if there is an obscure bug in their infrastructure that only affects your application. First you have to convince them to troubleshoot with you. Then you have to convince them to produce (or get their software vendor to produce) and deploy a patch.
So what are the solutions? Is PaaS doomed to never go beyond hobbyists? Of course not. The possible solutions are:
- Write a bug-free and high-performance PaaS infrastructure from the start, one that never needs to be changed in any way. How hard could it be? ;-)
- More realistically, narrowly define container types to reduce both the contract and the size of the underlying implementation of each instance. For example, rather than deploying a full JEE+SOA container componentize the application so that each component can deploy in a small container (e.g. a servlet engine, a process management engine, a rule engine, etc). As a result, the interface exposed by each container type can be more easily and fully tested. And because each instance is slimmer, it requires fewer patches over time.
- PaaS providers may give their users some amount of visibility and control over this. For example, by announcing upgrades ahead of time, providing updated nodes to test on early and allowing users to specify “freeze” periods where nothing changes (unless an urgent security patch is needed, presumably). Time for a Cloud “refresh” in ITIL/ITSM-land?
- The PaaS providers may also be able to facilitate debugging of infrastructure-related problem. For example by stamping the logs with a version ID for the infrastructure on the node that generated the log entry. And the ability to request that a test runs on a node with the same version. Keeping in mind that in a SOA / Composite world, the root cause of a problem found on one node may be a configuration change on a different node…
Some closing notes:
- Another incarnation of this problem is likely to show up in the form of PaaS certification. We should not assume that just because you use a PaaS you are the developer of the application. Why can’t I license an ISV app that runs on GAE? But then, what does the ISV certify against? A given PaaS provider, e.g. Google? A given version of the PaaS infrastructure (if there is such a thing… Google advertises versions of the GAE SDK, but not of the actual GAE runtime)? Or maybe a given PaaS software stack, e.g. the Oracle/Microsoft/IBM/VMWare/JBoss/etc, meaning that any Cloud provider who uses this software stack is certified?
- I have only discussed here changes to the underlying platform that do not change the contract (or at least only introduce backward-compatible changes, i.e. add APIs but don’t remove any). The matter of non-compatible platform updates (and version coexistence) is also a whole other ball of wax, one that comes with echoes of SOA governance discussions (because in PaaS we are talking about pure software contracts, not hardware or hardware-like contracts). Another area in which PaaS has larger challenges than IaaS.
- Finally, for an illustration of how a highly focused and specialized container cuts down on the need for config changes, look at this photo from earlier today during the presentation of JRockit Virtual Edition at Oracle Open World. This slide shows (in font size 3, don’t worry you’re not supposed to be able to read), the list of configuration files present on a normal Linux instance, versus a stripped-down (“JeOS”) Linux, versus JRockit VE.

By the way, JRockit VE is very interesting and the environment today is much more favorable than when BEA first did it, but that’s a topic for another post.
[UPDATED 2009/10/22: For more on this (in an EC2-centric context) see section 4 (“service problem resolution”) of this IBM paper. It ends with “another possible direction is to develop new mechanisms or APIs to enable cloud users to directly and automatically query and correlate application level events with lower level hardware information to better identify the root cause of the problem”.]
[UPDATES 2012/4/1: An example of a PaaS platform update which didn’t go well.]
Cloud catalog catalyst or cloud catalog cataclysm?
Like librarians, we IT wonks tend to like things cataloged. To date, the last instance of this has been SOA governance and its various registries and repositories. With UDDI limping along as some kind of organizing standard for the effort. One issue I have with UDDI is that its technical awkwardness is preventing us from learning from its failure to realize its ambitious goals (“e-business heaven”). It would be too easy to attribute the UDDI disappointment to UDDI. Rather, it should be laid at the feet of unreasonable initial expectations.
The SOA governance saga is still ongoing, now away from the spotlight and mostly from an implementation perspective rather than a standard perspective (by the way, what’s up with GIF?). Instead, the spotlight has turned to Cloud computing and that’s what we are supposedly going to control through cataloging next.
Earlier this year, I commented on the release of an ITSM catalog product for Cloud computing (though I was addressing the convergence of ITSM and Cloud computing more than catalogs per se).
More recently, Lori MacVittie related SOA governance to the need for Cloud catalogs. She makes some good points, but I also see some familiar-looking “irrational exuberance”. The idea of dynamically discovering and invoking a Cloud service reminds me too much of the initial “yellow pages” scenarios for UDDI (which quickly got dropped in favor of a more modest internal governance focus).
I am not convinced by the reason Lori gives for why things are different this time around (“one of the interesting things virtualization brings to the table that SOA did not is the ability to abstract management of services”). She argues that SOA governance only gave you access to the operational WSDL of a Web service, while Cloud catalogs will give you access to their management API. But if your service is an IT service, then your so-called management API (launch/configure/control VMs) is really its operational interface. The real management interface is the one Amazon uses under the cover and they are not going to expose it to you anymore than your bank is going to expose its application server administration console to you (if they do, move your money somewhere else before someone does it for you).
After all, isn’t SOA governance pretty close to a SaaS catalog which is itself a small part of the overall Cloud (IaaS+PaaS+SaaS) catalog question? If we still haven’t succeeded in the smaller scope, what are the odds of striking gold quickly in the larger effort?
Some analysts take a more pragmatic view, involving active brokers rather than simply a new DNS record type. I am doubtful about these brokers (0.2 probability, as Gartner would put it) but at least this moves the question onto business terms (leverage, control) rather than technical terms. Which is where the battle will be fought.
When it comes to Cloud catalogs, I think they are needed (if only for the categorization of Cloud services that they require) but will only play a supporting role, if any, in any move towards dynamic Cloud provisioning. As with SOA governance it’s as an internal tool, supported by strong processes, that they will be most useful.
Throughout human history, catalogs have been substitutes for control more often than instruments of control. Think of astronomy, zoology and… nephology for example. What kind will IT Cloud catalogs be?
Towards making Cloud services more consumable by enterprises
If you are a hard core network/system management person who has been very suspicious of all the ITIL/ITSM bullshit from the boss, and even more suspicious of the “Cloud” nonsense that occupies the interns while they should be monitoring the event console, then I have bad news for you: they are mating. Not the interns (as far as I know), I am talking about ITSM and the Cloud.
If, on the other hand, you are an ITSM and Cloud enthusiast who sees himself/herself leveraging all these nifty ITSM/BSM tools and shinny Cloud services to become the ultimate CIO, delivering unprecedented business value, compliance and IT efficiency from your iPhone at the beach, then you’ll see this marriage as good news, a sign that your move to Hawaii is approaching.
I am referring to the announcement by Rodrigo Flores that his company, newScale, has released a new product, newScale FrontOffice for Virtual Data Centers, to incorporate Cloud-based services in their IT Service Catalog.
This is not sexy but it’s the kind of support that some classes of enterprises will need in order to really make use of Cloud services. Eventually, Cloud providers are going to have to move their focus away from cool technology and developer evangelism towards making their services easily consumable by corporations. Otherwise they’ll be like an office supply store that doesn’t take American Express.
While the direction is very interesting I can’t comment on how much value this new product actually provides because the company seems to engage in anti-marketing activities. If you want to dig a bit deeper than the press release, you get redirected to this page which requires your info in order to download the “complimentary information brief”. The confirmation page promises an email “containing the information you requested within the next 30 minutes”. I thought that the info I requested was the brief. What I got instead was an email asking me to call them. I don’t know if it’s my unpronouncable last name of the oracle.com in my email address that scares them (I’d guess the latter) but that seems like a lot of precautions for a “complimentary information brief”. Unless this is an attempt to grab the “Cloud” buzzword with little meat to back it up (not that anyone would do this, of course). Hopefully they’ll make more information publicly available when they get around to it.
[UPDATED 2009/2/25: Via Coté, I just saw what I consider supporting envidence, from Gartner that, once we’re out of the early adopter phase, Cloud firms will need to focus less on pleasing developers and more on pleasing IT people: “But my observation from client interactions is that cloud adoption in established, larger organizations (my typical client is $100m+ in revenue) is, and will be, driven by Operations, and not by Development.”]
[UPDATED 2009/3/3: I got the PDF brief, thanks newScale (Ken and Mark). Many of the benefits it describes assumes that there is a pretty robust automation/provisioning infrastructure to back it up, in addition to the Catalog itself. E.g. the Catalog alone will not allow you to “shorten the provisioning cycle time to minutes instead of months”. The brief lists adapter kits to VMWare/EC2 and more internal-minded tools (HP and BMC, presumable through their Opsware and BladeLogic acquisitions respectively). So on the “public cloud” side it’s EC2 for now, not surprisingly. Integration with many of the Cloud tools (like RightScale) could be tricky since these tools bundle a catalog with the automation engine. If we ever do get a useful ontology of Cloud services this catalog would be a natural user for it, when it expands to other services beyond EC2 and tries to help you compare them. I guess newSCale wouldn’t appreciate if I provided a direct link to the PDF, so go request it to see for yourself.]
[UPDATED 2009/3/23: Speaking of managing your IT systems from your cell phone at the beach: VMWare vCenter Mobile Access.]
Filed under Cloud Computing, Everything, Governance, IT Systems Mgmt, ITIL, Mgmt integration, Utility computing
HP Systinet 3.00: now with more significant digits!
My ex-colleagues at HP have just released a new version of the HP Systinet SOA governance product. Congrats guys.
Just a question. What’s up with the “version 3.00” thing? We used to talk about “v1” and “v2”. Then came the whole “Web 2.0” silliness and we all replaced the “v” prefix with a “dot oh” suffix. Fine. But am I now supposed to say “dot oh oh”? And, more important, where will it stop? Is Santa Claus going to be bellowing “dot oh oh oh” later this year?
Or is it the price? Three dollars?
Since versioning is a big part of SOA management, I guess HP wanted to show that they had thought extra hard about the question and reflect this in their product name. In any case, no-one beats Oracle for granular version number (for example, JDeveloper 10.1.1.0.0 was released today).
More seriously, I noted with interest mentions of BPEL and SCA support in Systinet 3.00, but I couldn’t find any specific about what this means on the HP site. Anyone has more info? Also, no mention of GIF in the release announcement?
Comments Off on HP Systinet 3.00: now with more significant digits!
Filed under Application Mgmt, Everything, Governance, HP
Go Big Blue, go! Show them who’s the true friend of the little guy.
IBM’s well-publicized new policy for technology standards is an interesting development. The first image it conjured for cynical me is that of an aging Heavy Metal singer ranting against the rudeness of rap lyrics.
Like Charles, I don’t see IBM as an angel in this domain and yet I too think this is a commendable move on their part. Who better to stop a burglar than a (presumably) reformed burglar anyway? I hope this effort will succeed and I am glad to see that my colleague Jim Melton was involved in the discussion facilitated by IBM and that Trond supports it too.
My experience in standards (mostly from back in my HP days) only covers a small portion of IBM’s technology standards involvement of course. But in all instances, both IBM and Microsoft were key players (either through their participation or through their glaring refusal to participate). And within that sample (which does not include OOXML) my impression is that IBM did indeed play more cleanly than Microsoft.
They also mostly lost, while Microsoft mostly won. Whether there is a causality here is possible but not proven. IBM seems to have an ability to loose by winning: because they assign so many people to standards they wear out everybody else and at the end, they get the final document to be the way they want it (through the normal process, just by being relentless). But the specification is by then so over-engineered, so IBM-like in its approach and so late that it’s usually a Pyrrhic victory. Everybody else has moved on and IBM has on their hand something that’s a standard on paper but that only players in the IBM ecosystem implement. Pushing IBM’s CBE event format in WSDM, over-complicating aspects of WSRF like WS-ServiceGroup and butchering the use of SOAP headers in WS-ResourceTransfer to play nice with WebSphere are, in my mind, such examples. They can’t blame Microsoft for those.
Also, nobody forced them to tango with the devil in that whole WS-* saga. What they are saying now is similar in many ways to what Oracle was saying (about openness and fairness) throughout this decennia while Microsoft and IBM were privately defining machine to machine interoperability protocols for the enterprise. And they can’t blame standards for the way Microsoft eventually took advantage of them there, because they *chose* to do this outside of standards. I wish I had been a fly on the whole when this conversation took place:
IBM: We’re going to need a neutral DNS name for all these new XML namespaces. It wouldn’t be right to do it under ibm.com or microsoft.com.
Microsoft: You’re right. Hey, I just registered xmlsoap.org last week with the intent to launch a B2B forum for the detergent industry, but if you want we can use it for our Web services specs.
IBM: Man, that’s perfect. Let me give you twenty bucks to help pay the registration.
Microsoft: No, really, no big deal. It’s on me.
IBM: You’re too cool man.
But here I am, IBM-bashing again while the point of this post is to salute and support their attempt at reform. Bad, bad William.
OK, so now for some (hopefully) constructive remarks and suggestions.
I think commentaries and reports on the news have focused too much on the OOXML/ISO story. Sure it’s probably a big part of the motivation. But how much leverage does IBM really have on ISO? Technology standards is just a portion of what ISO does. And it’s not like ISO has much competition anyway, with its de jure international standing. Organizations like the JCP, DMTF and W3C have a lot more too lose if IBM really gets mad at them.
I think it’s clear that Microsoft is the target, but if ISO reform was the main prize, I don’t think IBM would go at it that way. ISO will only change in response to government pressure. If government influence is a necessary step, isn’t it cheaper and more direct for IBM to hire a couple more lobbyists than to try to rally the blogosphere? I think they really want to impact all standards setting organizations at the same time. If ISO happens to be one of those improved in the process, that’s gravy.
IBM calls its report “standards for standards” (at least that’s the file name). I think (and hope) the double entendre is voluntary. It’s not just a matter a raising the (moral and operational) standards of standards organizations. It should also be an occasion to standardize how they work, to make them more similar to one another.
Follow me for a second here. One of the main problems with many organizations is their opacity. They have boards, task forces, strategic committees, etc. Membership in the organization is stratified, based mostly on how much you are willing to pay. I would guess that most organizations couldn’t make ends meet if all member companies paid the “base membership” fee. They need a dozen companies to pay the “leadership” fee to fund their operations. For these companies to agree to the higher price of participation, they need something in return. They need to have more access than the others. Therefore, some level of access must be denied to the base members (and even more to the non-members, which is why many such organizations make almost no information publicly available).
They are not opaque by accident, they are opaque by design because they need to be in order to be funded. There are two ways to fix this. One is to have fewer organizations, such that the fixed costs of running an organization can be more widely spread. But technology is very specialized and there is value in having organizations that are focused and populated by domain experts. The other way is to drastically reduce the cost of running a standards organization. That’s where standardization of standards organizations comes in. If the development processes, IP policies, bylaws and tools were commonly shared among standards organizations, it would be a lot cheaper to run one.
Today, I can start a new open source project for free on Sourceforge. I can pick one of the clearly-identified open source licenses that have been pre-defined. I can use the usual source control, collaboration and bug reporting tools. Not only is it almost free, my users will know right away how to participate. Why isnt’ it the same for standards organizations? Or only so partially. I know that Kavi is used by many standards organizations. I’ve used their tool both as a DMTF participant and an OASIS participant. And it doesn’t really fit either perfectly because the processes are slightly different. Ballots are conducted differently, attendance rules are different, document visibility rules are different, roles are different, etc.
It sounds superficial, but I am convinced that a more standardized approach to IP policies, organization bylaws and specification development processes would result in big savings that would open the door to much more transparency.
Oh yeah, you’d also have to drop the boondoggle plenary sessions in resorts all over the world. Painful, I know.
Sure there are other costs, such as marketing costs. But fully transparent organizations, by making their products more easily accessible to users, have a much lower need to use traditional marketing to get the word out. In the same way that open source software companies get most of their marketing via their user community. Consistency among standards organizations would also make it a lot easier for small companies to participate since anyone who’s learned the rules once can be effective right away in a new organization.
I want to end with a note of caution directed at IBM. You have responsibilities. I hope you realize that at this point, approximately 20% of all airplane seats are occupied by IBM employees going to or coming back from some standards-related meeting. The airlines are hurting already, you can’t pull out at once. And who will drive all these rental Chevys? Who will eat all the bad sushi in airport food courts and Benihana restaurants?
[UPDATED 2008/10/20: From Tim Bray, another example of IBM loosing by winning in standards: “Unfortunately, that spec [XML 1.1] came with excess baggage, namely changed rules on what constitutes white-space, rammed through by IBM for the convenience of their mainframe customers. In any case, XML 1.1 has been widely ignored”.]
Filed under Conference, Everything, Governance, IBM, ISO, Microsoft, OOXML, Open source, Standards
SOA management: round-up of recent news
It started with a checkpoint on “the state of SOA monitoring and management” by Doug McClure. A good set of questions and a good list of “usual suspects” (but how much did Actional pay to be listed twice?).
Then came this good article from AMIS’ Lucas Jellema reporting on what he learned during a recent Oracle SOA Partner event. He pokes fun at Oracle/BEA for conveniently tweaking their “this is what you need” story to align with the “this is what we offer” part (I am shocked, SHOCKED to hear that a vendor would do that, let alone my employer). But the real focus of his article is to describe the importance of design-time SOA governance (integrated with the other parts of the lifecycle). He does a good job at describing some of the value of the consolidated Oracle/BEA offering.
I couldn’t help smiling when I read this paragraph:
“It struck me that most of what applies in terms of Governance to SOA assets, also applies to other assets in any software engineering process. Trying to manage reusable components for example or even implementing a good maintenance approach for a non-SOA application is a tremendous challenge, that has many parallels with SOA Governance. And to some extent could benefit from applying a tooling infrastructure such as provided by the Enterprise Repository… Well, just a thought for now. I need to know more about the ER before jumping to conclusions.”
If my memory serves me right, the original Flashline product that BEA acquired (what became the Enterprise Repository) was just that, a generic metadata repository for software assets, not something SOA-specific. It’s ironic to see Lucas look at it now and think “hey, maybe this SOA repository can be used for non-SOA apps”. Back to the future. And BTW, Lucas is right about this applicability, as Michael Stamback soon confirmed.
Still in Oracle-land, a few days later came the news that Oracle is acquiring ClearApp. Doug’s post was more about runtime governance (which he calls monitoring/management, and I tend to agree with him even though this is fighting the tide) than design-time governance. In that sense, the ClearApp announcement is more relevant to his questions than Lucas’ post. The ClearApp capabilities fit squarely with Doug’s request for “providing the right level of business visibility into the SOA environment and more importantly the e2e business services, applications, transactions, processes and activities”, as I tried to illustrate before.
More recently, Software AG announced an OEM partnership with Actional (part of Progress) to bring runtime data to its CentraSite registry (which, I assume, comes from the Infravio acquisition by WebMethods before it itself was swallowed by Software AG).
Actional’s Dan Foody of course applauds and uses the opportunity to dispel some FUD (“Actional is tightly tied with Sonic”) and also generate some new FUD (“no vendor had even a half decent offering on both sides [design-time and runtime] of the fence”).
Neil Macehiter has a more neutral commentary on the Software AG news. His analysis ends with some questions about what this means for Amberpoint. Maybe it’s time to restart the “Microsoft might acquire Amberpoint” rumor.
Speaking of Microsoft, the drum roll is getting louder in anticipation for Oslo making its debut at the upcoming PDC. That’s a topic for another post though.
This Oslo detour is a little bit off topic, but not so much. The way Don Box and team envision that giant software model shaping up they probably picture what’s called today “SOA Governance” as just a small application that an intern can build in a week on top of the Oslo repository. Or I am exaggerating?
Unlike Dan Foody I like the approach of keeping SOA Governance closely integrated with the development and IT management infrastructures. At the cost of quoting myself (if I don’t, who will?) “it’s not just about managing Web services or Web sites, it’s about managing the whole SOA application”.
[UPDATED 2008/9/23: It looks like the relationship between CentraSite and Infravio is a little bit more complex than I assumed.]
Comments Off on SOA management: round-up of recent news
Filed under Application Mgmt, Everything, Governance, IT Systems Mgmt, Manageability, Mgmt integration, Oracle, Oslo, SOAP
IGF and GIF: it’s not a typo
With the Oracle announcements at the RSA conference this month (things like Oracle Role Manager and this white paper), the Identity Governance Framework (IGF) is back in the news. And since HP publicly released the Governance Interoperability Framework (GIF) earlier this year, there is some potential for confusion between the two (akin to the OSGi/OGSI confusion). I am not an author or even an expert in either, but I know enough about both that I can at least help reduce the confusion.
They are both frameworks, they are both about governance, they both try to enable interoperability, they both define XML formats, they were both privately designed and they are both pushed by their authors (and supporters) towards standardization. To add to the confusion, Oracle is listed as a supporter of HP’s GIF and HP is listed as a supporter of Oracle’s IGF.
And yet they are very different.
GIF is an attempt to address SOA governance, which mostly relates to the lifecycle of services and their artifacts (like WSDL, XSD and policies). So you can track versions, deployment status, ownership, dependencies, etc. HP is making the specification available to all (here but you need to register) and has talked about submission to a standards body but as far as I know this hasn’t happened yet.
IGF is a set of specifications and APIs that pull access policy for identity related information out of the application logic and into well-understood XML declarations. With the goal of better controlling the flow of such information. The keystones are the CARML specification used to describe what identity related information an application needs and its counterpart the AAPML specification, used to describe the rules and constraints that an application puts on usage of the identity-related information it owns. The framework also defines relevant roles and service interfaces. Unlike GIF, which is still controlled by HP, IGF is now under the control of the Liberty Alliance Project. Oracle is just one participant (albeit a leading one).
Could they ever meet?
A Web service managed through a GIF-like SOA governance system could have policies related to accessing identity-related information, as addressed by IGF (and realized through CARML and AAPML elements). GIF doesn’t really care about the content of the policies. Studying the positions of the IGF and GIF specifications relative to WS-Policy would be a good way to concretely understand how they operate at a different level from one another. While there could theoretically be situations in which IGF and GIF are both involved, they do not do the same thing and have no interdependency whatsoever.
[UPDATED 2008/4/18: Phil Hunt (co-author of IGF) has a blog where he often writes about IGF. He also wrote a good overview of IGF and its applicability to governance and SOX-style compliance.]
Comments Off on IGF and GIF: it’s not a typo
Filed under Everything, Governance, Identity theft, Oracle, Security, Specs, Standards
Ontology governance?
How do organizations that make heavy use of ontologies implement design-time governance?
A quick search tonight didn’t return much on that topic (note to Google: “governance” is not synonymous with “government”). Am I imagining a problem that doesn’t really exist? Am I too influenced by SOA governance use cases?
Sure, a lot of the pain that SOA governance tries to address is self-inflicted. When used to deal with contract versioning hell (hello XSD) and brittle implementations (hello stub generation), SOA governance is just a bandage on a self-shot foot. Thanks to the open-world assumption, deliberate modeling decisions (e.g. no ordering unless required), a very simple metamodel and maybe some built-in versioning support (e.g. owl:backwardCompatibleWith, owl:incompatibleWith, owl:priorVersion, owl:versionInfo, etc, with which I don’t have much experience), in the RDF/OWL world these self-inflicted wounds are a lot less likely.
On the other hand, there are aspects of SOA governance that are more than lipstick on a pig and it seems that some of those should apply to ontology governance. You still need to discover artifacts. You may still have incompatible versions. You still have to deal with the collaborative aspects of having different people responsible for different parts. You may still need a review/approval process, or other lifecycle aspects. And that’s just at the ontology design level. At the service level you have the same questions of discovery, protocol, query capabilities, etc.
What are the best practices for this in the semantic world? What are the tools? Or alternatively, why is this less important than I think?
Maybe this upcoming book will have some answers to these practical concerns. It was recommended to me by someone who reviewed a draft and had good things to say about it, if not quite as enthusiastically as Toru Ishida from Kyoto University (from the editorial reviews on Amazon):
“At the time when the world needs to find consensus on a wide range of subjects, publication of this book carries special importance. Crossing over East-West cultural differences, I hope semantic web technology contributes to bridge different ontologies and helps build the foundation for consensus towards the global community.”
If semantic technologies can bring world peace, surely they can help with IT management integration…
PS: if you got to this page through a Web search along the lines of “XSD versioning hell” I am sorry that you won’t find the solution to your problems here. Tim Ewald and Dave Orchard have recommendations for you. But the fact that XML experts like Tim and Dave have some kind of (partial) workarounds doesn’t mean the industry doesn’t have a problem. Or you can put your hopes in XSD 1.1 if you are so inclined (see these slides for an overview of the versioning-related changes).
Filed under Everything, Governance, OWL, Semantic tech
Fog Computing
As happened with Salesforce.com a couple of years ago, Amazon S3 is having serious problems serving its customers today. Like Salesforce.com at the time, Amazon is criticized for not being transparent enough about it.
Right now, “cloud computing” is also “fog computing”. There is very little visibility (if any) into the infrastructure that is being consumed as a service. Part of this is a feature (a key reason for using these services is freedom from low-level administration) but part of it is a defect.
The clamor for Amazon to provide more updates about the outage on the AWS blog is a bit misplaced in that sense. Sure, that kind of visibility (“well folks, it was bring-your-hamster-to-work day at the Amazon data center today and turns out they love chewing cables. Our bad. The local animal refuge is sending us all their cats to help deal with the mess. Stay tuned”) gives a warm fuzzy (!) feeling but that’s not very actionable.
It’s not a matter for Amazon of giving access to its entire management stack (even in view-only mode) to its customers. It’s a matter of extracting customer-facing metrics that are relevant and exposing them in a way that can be consumed by the customer’s IT management tools. So they can be integrated in the overall IT decisions. And it’s not just monitoring even though that’s a good start. Saying “I don’t want to know how you run the service, all I care is what you do for me”, only takes you so far in enterprise computing. This opacity is a great way to hide single points of failure:
I predict (as usual, no date) that we will see companies that thought they were hedging their bets by using two different SaaS providers only to realize, on the day Amazon goes down again, that both SaaS providers were hosting on Amazon EC2 (or equivalent). Or, on the day a BT building catches fire, that both SaaS providers had their data centers there.
Just another version of “for diversification, I had a high yield fund and a low risk fund. I didn’t really read the prospectus. Who would have guessed that they were both loaded with mortgage debt?”
More about IT management in a utility computing world in a previous entry.
[UPDATED: Things have improved a bit since writing this. Amazon now has a status panel. But it’s still limited to monitoring. Today it’s Google App Engine who is taking the heat.]
Comments Off on Fog Computing
Filed under Everything, Governance, IT Systems Mgmt, Utility computing
HP’s GIFt to the SOA world
I just noticed a press release from HP to announce the release of GIF (the Governance Interoperability Framework). In short, GIF is a specification that describes how to use the HP SOA Registry for governance tasks that go beyond what UDDI can do. It has been around for a long time inside Systinet then Mercury then HP and some partners had been somewhat enrolled in the program (whatever that meant) but it wasn’t clear what HP was really planning to do with it. Looks like they have decided to put some muscle into it by attracting more partners and releasing it. Or at least announcing that they would release it. I can’t find it on the HP site so I can’t see if and how the specification changed since when I was in HP. It will be interesting to see if they present it as a neutral specification of which the HP SOA Registry is one implementation or as something that requires that registry.
I also looked for it on Wikipedia since the press release declares that it will be made available there but to no avail. That part puzzles me a bit since this would be pretty atypical for Wikipedia. At most there could be an article about GIF that links to the specification on hp.com. And even then, you’d have to convince Wikipedia editors that the topic is “worthy of notice”. Or maybe they meant to refer to an HP wiki and some confused editor turned that into Wikipedia?
The press release has a few additional items (yet more fancy-sounding SOA offering from HP Services and some new OEM-friendly packaging for the Registry) but they don’t seem too exciting to me. The GIF action is what could be interesting if things really get moving on this. In any case, congratulations to Luc and Dave.
[UPDATED 2008/2/4: turns out Luc isn’t at HP anymore, he’s joined Active Endpoints as Senior Director of Product Management. Double congrats then, one set for the past work on GIF and the other for the new job.]
[UPDATED 2008/2/5: there is now a Wikipedia page with a description of GIF. But still no sign of the specification itself on the HP GIF page.]
[UPDATED 2008/3/16: you can now download the spec (but you’ll need to register with HP first).]
Filed under Everything, Governance, HP, Specs