The Functional Model of PaaS is nice, but the Operational Model matters more.
Let’s first define these terms.
The Functional Model is what the platform does for you. For example, in the case of AWS S3, it means storing objects and making them accessible via HTTP.
The Operational Model is how you consume the platform service. How you request it, how you manage it, how much it costs, basically the total sum of the responsibility you have to accept if you use the features in the Functional Model. In the case of S3, the Operational Model is made of an API/UI to manage it, a bill that comes every month, and a support channel which depends on the contract you bought.
The Operational Model is where the S (“service”) in “PaaS” takes over from the P (“platform”). The Operational Model is not always as glamorous as new runtime features. But it’s what makes Cloud Cloud. If a provider doesn’t offer the specific platform feature your application developers desire, you can work around it. Either by using a slightly-less optimal approach or by building the feature yourself on top of lower-level building blocks (as Netflix did with Cassandra on EC2 before DynamoDB was an option). But if your provider doesn’t offer an Operational Model that supports your processes and business requirements, then you’re getting a hipster’s app server, not a real PaaS. It doesn’t matter how easy it was to put together a proof-of-concept on top of that PaaS if using it in production is playing Russian roulette with your business.
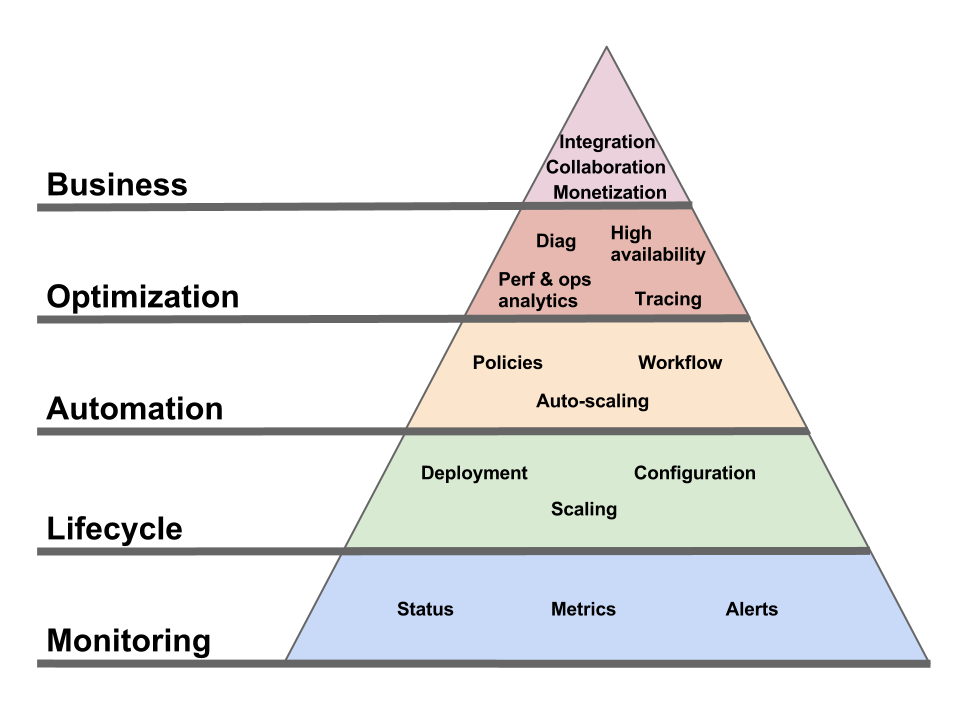
If the Cloud Operational Model is so important, what defines it and what makes a good Operational Model? In short, the Operational Model must be able to integrate with the consumer’s key processes: the business processes, the development processes, the IT processes, the customer support processes, the compliance processes, etc.
To make things more concrete, here are some of the key aspects of the Operational Model.
Deployment / configuration / management
I won’t spend much time on this one, as it’s the most understood aspect. Most Clouds offer both a UI and an API to let you provision and control the artifacts (e.g. VMs, application containers, etc) via which you access the PaaS functional interface. But, while necessary, this API is only a piece of a complete operational interface.
Support
What happens when things go wrong? What support channels do you have access to? Every Cloud provider will show you a list of support options, but what’s really behind these options? And do they have the capability (technical and logistical) to handle all your issues? Do they have deep expertise in all the software components that make up their infrastructure (especially in PaaS) from top to bottom? Do they run their own datacenter or do they themselves rely on a customer support channel for any issue at that level?
SLAs
I personally think discussions around SLAs are overblown (it seems like people try to reduce the entire Cloud Operational Model to a provisioning API plus an SLA, which is comically simplistic). But SLAs are indeed part of the Operational Model.
Infrastructure change management
It’s very nice how, in a PaaS setting, the Cloud provider takes care of all change management tasks (including patching) for the infrastructure. But the fact that your Cloud provider and you agree on this doesn’t neutralize Murphy’s law any more than me wearing Michael Jordan sneakers neutralizes the law of gravity when I (try to) dunk.
In other words, if a patch or update is worth testing in a staging environment if you were to apply it on-premise, what makes you think that it’s less likely to cause a problem if it’s the Cloud provider who rolls it out? Sure, in most cases it will work just fine and you can sing the praise of “NoOps”. Until the day when things go wrong, your users are affected and you’re taken completely off-guard. Good luck debugging that problem, when you don’t even know that an infrastructure change is being rolled out and when it might not even have been rolled out uniformly across all instances of your application.
How is that handled in your provider’s Operational Model? Do you have visibility into the change schedule? Do you have the option to test your application on the new infrastructure or to at least influence in any way how and when the change gets rolled out to your instances?
Note: I’ve covered this in more details before and so has Chris Hoff.
Diagnostic
Developers have assembled a panoply of diagnostic tools (memory/thread analysis, BTM, user experience, logging, tracing…) for the on-premise model. Many of these won’t work in PaaS settings because they require a console on the local machine, or an agent, or a specific port open, or a specific feature enabled in the runtime. But the need doesn’t go away. How does your PaaS Operational Model support that process?
Customer support
You’re a customer of your Cloud, but you have customers of your own and you have to support them. Do you have the tools to react to their issues involving your Cloud-deployed application? Can you link their service requests with the related actions and data exposed via your Cloud’s operational interface?
Security / compliance
Security is part of what a Cloud provider has to worry about. The problem is, it’s a very relative concept. The issue is not what security the Cloud provider needs, it’s what security its customers need. They have requirements. They have mandates. They have regulations and audits. In short, they have their own security processes. The key question, from their perspective, is not whether the provider’s security is “good”, but whether it accommodates their own security process. Which is why security is not a “trust us” black box (I don’t think anyone has coined “NoSec” yet, but it can’t be far behind “NoOps”) but an integral part of the Cloud Operational Model.
Business management
The oft-repeated mantra is that Cloud replaces capital expenses (CapExp) with operational expenses (OpEx). There’s a lot more to it than that, but it surely contributes a lot to OpEx and that needs to be managed. How does the Cloud Operational Model support this? Are buyer-side roles clearly identified (who can create an account, who can deploy a service instance, who can manage a deployed instance, etc) and do they map well to the organizational structure of the consumer organization? Can charges be segmented and attributed to various cost centers? Can quotas be set? Can consumption/cost projections be run?
We all (at least those of us who aren’t accountants) love a great story about how some employee used a credit card to get from the Cloud something that the normal corporate process would not allow (or at too high a cost). These are fun for a while, but it’s not sustainable. This doesn’t mean organizations will not be able to take advantage of the flexibility of Cloud, but they will only be able to do it if the Cloud Operational Model provides the needed support to meet the requirements of internal control processes.
Conclusion
Some of the ways in which the Cloud Operational Model materializes can be unexpected. They can seem old-fashioned. Let’s take Amazon Web Services (AWS) as an example. When they started, ownership of AWS resources was tied to an individual user’s Amazon account. That’s a big Operational Model no-no. They’ve moved past that point. As an illustration of how the Operational Model materializes, here are some of the features that are part of Amazon’s:
- You can Fedex a drive and have Amazon load the data to S3.
- You can optimize your costs for flexible workloads via spot instances.
- The monitoring console (and API) will let you know ahead of time (when possible) which instances need to be rebooted and which will need to be terminated because they run on a soon-to-be-decommissioned server. Now you could argue that it’s a limitation of the AWS platform (lack of live migration) but that’s not the point here. Limitations exists and the role of the Operational Model is to provide the tools to handle them in an acceptable way.
- Amazon has a program to put customers in touch with qualified System Integrators.
- You can use your Amazon support channel for questions related to some 3rd party software (though I don’t know what the depth of that support is).
- To support your security and compliance requirements, AWS support multi-factor authentication and has achieved some certifications and accreditations.
- Instance status checks can help streamline your diagnostic flows.
These Operational Model features don’t generate nearly as much discussion as new Functional Model features (“oh, look, a NoSQL AWS service!”) . That’s OK. The Operational Model doesn’t seek the limelight.
Business applications are involved, in some form, in almost every activity taking place in a company. Those activities take many different forms, from a developer debugging an application to an executive examining operational expenses. The PaaS Operational Model must meet their needs.